At the upcoming ACM Conference on Computer and Communications Security (CCS) I’ll be presenting a paper on Automatic Exploit Generation (AEG), with the same title as this blog post. You can find the paper here. In the paper I discuss a system for automatically discovering primitives and constructing exploits using heap overflows in interpreters. The approach taken in the paper is a bit different from most other AEG solutions in that it is entirely greybox, relying on lightweight instrumentation and various kinds of fuzzing-esque input generation. The following diagram shows the stages of the system, and each is explained in detail in the paper.

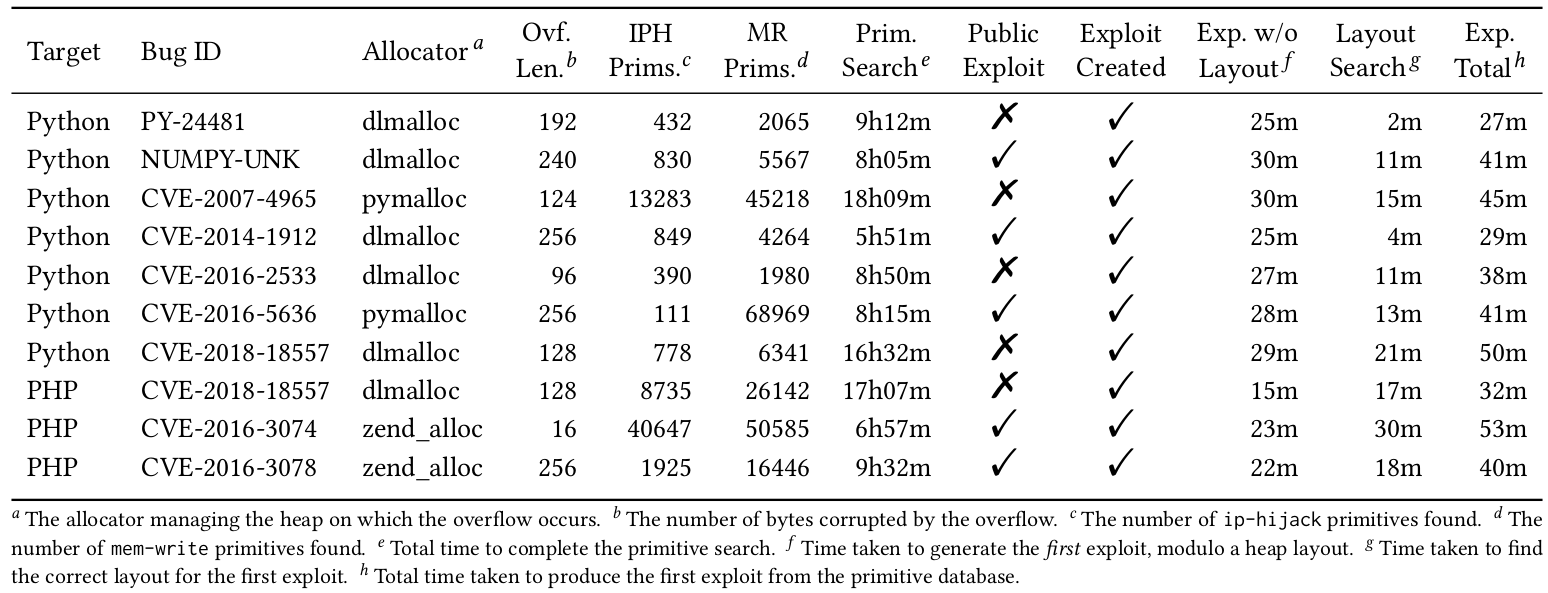
In terms of evaluation, I used 10 vulnerabilities in the PHP and Python interpreters as tests, and provided these as input to Gollum for it to use in its search for primitives and to build exploits.
There are three main takeaways from the paper that I think worth highlighting (see paper for details!):
1. AEG is a multi-stage process, and by breaking the problem into distinct phases it becomes reasonable to attack a number of those phases using a fuzzing-esque combination of lightweight instrumentation and relatively dumb input generation. Traditionally, AEG systems used symbolic execution as their main driver and, while there are some positives to this, it also encounters all of the scalability issues that one expects with symbolic execution. In a paper last year at USENIX Security, I showed how with lightweight instrumentation one could use the existing tests of an application, combined with a fuzzer, to discover language fragments that could be used to perform heap layout manipulation, as well as to allocate interesting objects to corrupt. In the upcoming CCS paper, I show how one can use a similar approach to also discover exploitation primitives, and in certain situations to even build exploits. It’s worth noting that in their paper on FUZE, Wu et al. take a similar approach, and you should check out their paper for another example system. My guess is that in the next couple of years fuzzing-driven exploit generation is likely to be the predominant flavour, with symbolic execution being leveraged in scenarios where its bit-precise reasoning is required and state-space explosion can be limited.
2. When automatically constructing exploits for heap overflows one needs a solution for achieving the desired heap layout and then another solution for building the rest of the exploit. In the CCS paper I introduce the idea of lazy resolution of tasks in exploit generation. Essentially, this is an approach for solving the problems of heap layout manipulation and the rest of the exploit generation in the reverse order. The reason one might want to do this is simple: in an engine where the process for achieving the heap layout can potentially take much longer than the one to create the rest of the exploit (as is the case in Gollum), it makes sense to check if it is feasible to produce an exploit under the assumption that the more difficult problem is solvable, and then only bother to solve it if it enables an exploit. Specifically, in the case of Gollum, I constructed a heap allocator that allows you to request a particular layout, then you can attempt to generate the exploit under the assumption the layout holds, and only later figure out how to achieve it once you know it enables the exploit.
I think this sort of idea might be more generally useful in exploit generation for other vulnerability types as well, e.g. in an exploit generation system for race conditions, one could have a solution that allows one to request a particular scheduling, check if that scheduling enables an exploit, and only then search for the input required to provide the scheduling. Such an approach also allows for a hybrid of manual and automatic components. For example, in our case we assume a heap layout holds, then generate an exploit from it, and finally try and automatically solve the heap layout problem. Our solution for the heap layout problem has a number of preconditions though, so in cases where those conditions are not met we can still automatically generate the rest of the exploit under the assumption that the layout problem is solved, and eventually the exploit developer can manually solve it themselves.
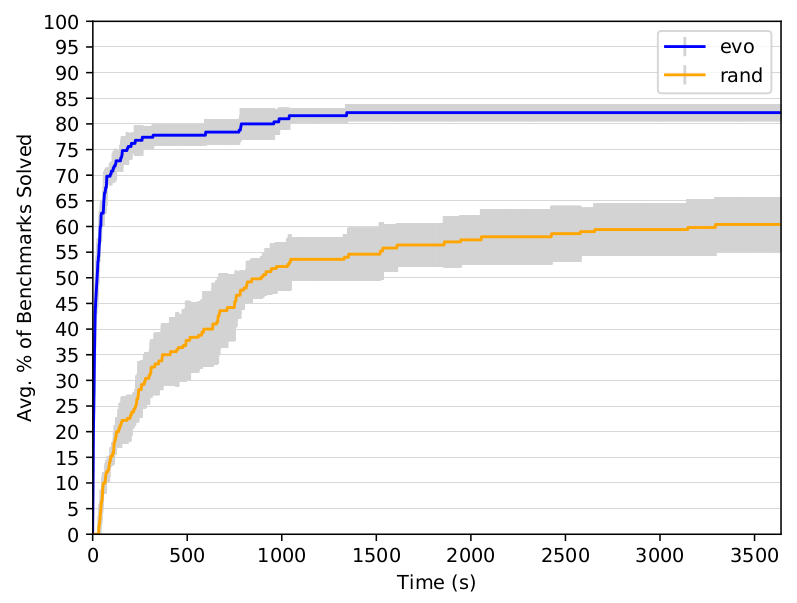
3. In last year’s USENIX Security paper I discussed a random search algorithm for doing heap layout manipulation. As you might expect, a genetic algorithm, optimising for distance between the two chunks you want to place adjacent to each other, can perform this task far better, albeit at the cost of a more complicated and time consuming implementation.