Recently I ran an experiment where I built agents on top of Opus 4.5 and GPT-5.2 and then challenged them to write exploits for a zeroday vulnerability in the QuickJS Javascript interpreter. I added a variety of modern exploit mitigations, various constraints (like assuming an unknown heap starting state, or forbidding hardcoded offsets in the exploits) and different objectives (spawn a shell, write a file, connect back to a command and control server). The agents succeeded in building over 40 distinct exploits across 6 different scenarios, and GPT-5.2 solved every scenario. Opus 4.5 solved all but two. I’ve put a technical write-up of the experiments and the results on Github, as well as the code to reproduce the experiments.
In this post I’m going to focus on the main conclusion I’ve drawn from this work, which is that we should prepare for the industrialisation of many of the constituent parts of offensive cyber security. We should start assuming that in the near future the limiting factor on a state or group’s ability to develop exploits, break into networks, escalate privileges and remain in those networks, is going to be their token throughput over time, and not the number of hackers they employ. Nothing is certain, but we would be better off having wasted effort thinking through this scenario and have it not happen, than be unprepared if it does.
A Brief Overview of the Experiment
All of the code to re-run the experiments, a detailed write-up of them, and the raw data the agents produced are on Github, but just to give a flavour of what the agents accomplished:
Both agents turned the QuickJS vulnerability into an ‘API’ to allow them to read and arbitrarily modify the address space of the target process. As the vulnerability is a zeroday with no public exploits for it, this capability had to be developed by the agents through reading source code, debugging and trial and error. A sample of the notable exploits is here and I have written up one of them in detail here.
They solved most challenges in less than an hour and relatively cheaply. I set a token limit of 30M per agent run and ran ten runs per agent. This was more than enough to solve all but the hardest task. With Opus 4.5 30M total tokens (input and output) ends up costing about $30 USD.
In the hardest task I challenged GPT-5.2 it to figure out how to write a specified string to a specified path on disk, while the following protections were enabled: address space layout randomisation, non-executable memory, full RELRO, fine-grained CFI on the QuickJS binary, hardware-enforced shadow-stack, a seccomp sandbox to prevent shell execution, and a build of QuickJS where I had stripped all functionality in it for accessing the operating system and file system. To write a file you need to chain multiple function calls, but the shadow-stack prevents ROP and the sandbox prevents simply spawning a shell process to solve the problem. GPT-5.2 came up with a clever solution involving chaining 7 function calls through glibc’s exit handler mechanism. The full exploit is here and an explanation of the solution is here. It took the agent 50M tokens and just over 3 hours to solve this, for a cost of about $50 for that agent run. (As I was running four agents in parallel the true cost was closer to $150).
Before going on there are two important caveats that need to be kept in mind with these experiments:
While QuickJS is a real Javascript interpreter, it is an order of magnitude less code, and at least an order of magnitude less complex, than the Javascript interpreters in Chrome and Firefox. We can observe the exploits produced for QuickJS and the manner in which they were produced and conclude, as I have, that it appears that LLMs are likely to solve these problems either now or in the near future, but we can’t say definitively that they can without spending the tokens and seeing it happen.
The exploits generated do not demonstrate novel, generic breaks in any of the protection mechanisms. They take advantage of known flaws in those protection mechanisms and gaps that exist in real deployments of them. These are the same gaps that human exploit developers take advantage of, as they also typically do not come up with novel breaks of exploit mitigations for each exploit. I’ve explained those gaps in detail here. What is novel are the overall exploit chains. This is true by definition as the QuickJS vulnerability was previously unknown until I found it (or, more correctly: my Opus 4.5 vulnerability discovery agent found it). The approach GPT-5.2 took to solving the hardest challenge mentioned above was also novel to me at least, and I haven’t been able to find any example of it written down online. However, I wouldn’t be surprised if it’s known by CTF players and professional exploit developers, and just not written down anywhere.
The Industrialisation of Intrusion
By ‘industrialisation’ I mean that the ability of an organisation to complete a task will be limited by the number of tokens they can throw at that task. In order for a task to be ‘industrialised’ in this way it needs two things:
An LLM-based agent must be able to search the solution space. It must have an environment in which to operate, appropriate tools, and not require human assistance. The ability to do true ‘search’, and cover more of the solution space as more tokens are spent also requires some baseline capability from the model to process information, react to it, and make sensible decisions that move the search forward. It looks like Opus 4.5 and GPT-5.2 possess this in my experiments. It will be interesting to see how they do against a much larger space, like v8 or Firefox.
The agent must have some way to verify its solution. The verifier needs to be accurate, fast and again not involve a human.
Exploit development is the ideal case for industrialisation. An environment is easy to construct, the tools required to help solve it are well understood, and verification is straightforward. I have written up the verification process I used for the experiments here, but the summary is: an exploit tends to involve building a capability to allow you to do something you shouldn’t be able to do. If, after running the exploit, you can do that thing, then you’ve won. For example, some of the experiments involved writing an exploit to spawn a shell from the Javascript process. To verify this the verification harness starts a listener on a particular local port, runs the Javascript interpreter and then pipes a command into it to run a command line utility that connects to that local port. As the Javascript interpreter has no ability to do any sort of network connections, or spawning of another process in normal execution, you know that if you receive the connect back then the exploit works as the shell that it started has run the command line utility you sent to it.
There is a third attribute of problems in this space that may influence how/when they are industrialisable: if an agent can solve a problem in an offline setting and then use its solution, then it maps to the sort of large scale solution search that models seem to be good at today. If offline search isn’t feasible, and the agent needs to find a solution while interacting with the real environment, and that environment has the attribute that certain actions by the agent permanently terminate the search, then industrialisation may be more difficult. Or, at least, it’s less apparent that the capabilities of current LLMs map directly to problems with this attribute.
There are several tasks involved in cyber intrusions that have this third property: initial access via exploitation, lateral movement, maintaining access, and the use of access to do espionage (i.e. exfiltrate data). You can’t perform the entire search ahead of time and then use the solution. Some amount of search has to take place in the real environment, and that environment is adversarial in that if a wrong action is taken it can terminate the entire search. i.e. the agent is detected and kicked out of the network, and potentially the entire operation is burned. For these tasks I think my current experiments provide less information. They are fundamentally not about trading tokens for search space coverage. That said, if we think we can build models for automating coding and SRE work, then it would seem unusual to think that these sorts of hacking-related tasks are going to be impossible.
Where are we now?
We are already at a point where with vulnerability discovery and exploit development you can trade tokens for real results. There’s evidence for this from the Aardvark project at OpenAI where they have said they’re seeing this sort of result: the more tokens you spend, the more bugs you find, and the better quality those bugs are. You can also see it in my experiments. As the challenges got harder I was able to spend more and more tokens to keep finding solutions. Eventually the limiting factor was my budget, not the models. I would be more surprised if this isn’t industrialised by LLMs, than if it is.
For the other tasks involved in hacking/cyber intrusion we have to speculate. There’s less public information on how LLMs perform on these tasks in real environments (for obvious reasons). We have the report from Anthropic on the Chinese hacking team using their API to orchestrate attacks, so we can at least conclude that organisations are trying to get this to work. One hint that we might not be yet at a place where post-access hacking-related tasks are automated is that there don’t appear to be any companies that have entirely automated SRE work (or at least, that I am aware of).
The types of problems that you encounter if you want to automate the work of SREs, system admins and developers that manage production networks are conceptually similar to those of a hacker operating within an adversary’s network. An agent for SRE can’t just do arbitrary search for solutions without considering the consequences of actions. There are actions that if it takes the search is terminated and it loses permanently (i.e. dropping the production database). While we might not get public confirmation that the hacking-related tasks with this third property are now automatable, we do have a ‘canary’. If there are companies successfully selling agents to automate the work of an SRE, and using general purpose models from frontier labs, then it’s more likely that those same models can be used to automate a variety of hacking-related tasks where an agent needs to operate within the adversary’s network.
Conclusion
These experiments shifted my expectations regarding what is and is not likely to get automated in the cyber domain, and my time line for that. It also left me with a bit of a wish list from the AI companies and other entities doing evaluations.
Right now, I don’t think we have a clear idea of the real abilities of current generation models. The reason for that is that CTF-based evaluations and evaluations using synthetic data or old vulnerabilities just aren’t that informative when your question relates to finding and exploiting zerodays in hard targets. I would strongly urge the teams at frontier labs that are evaluating model capabilities, as well as for AI Security Institutes, to consider evaluating their models against real, hard, targets using zeroday vulnerabilities and reporting those evaluations publicly. With the next major release from a frontier lab I would love to read something like “We spent X billion tokens running our agents against the Linux kernel and Firefox and produced Y exploits“. It doesn’t matter if Y=0. What matters is that X is some very large number. Both companies have strong security teams so it’s entirely possible they are already moving towards this. OpenAI already have the Aardvark project and it would be very helpful to pair that with a project trying to exploit the vulnerabilities they are already finding.
For the AI Security Institutes it’s would be worth spending time identifying gaps in the evaluations that the model companies are doing, and working with them to get those gaps addressed. For example, I’m almost certain that you could drop the firmware from a huge number of IoT devices (routers, IP cameras, etc) into an agent based on Opus 4.5 or GPT-5.2 and get functioning exploits out the other end in less a week of work. It’s not ideal that evaluations focus on CTFs, synthetic environments and old vulnerabilities, but don’t provide this sort of direct assessment against real targets.
In general, if you’re a researcher or engineer, I would encourage you to pick the most interesting exploitation related problem you can think of, spend as many tokens as you can afford on it, and write up the results. You may be surprised by how well it works.
Hopefully the source code for my experiments will be of some use in that.
In this post I’ll show you how I found a zeroday vulnerability in the Linux kernel using OpenAI’s o3 model. I found the vulnerability with nothing more complicated than the o3 API – no scaffolding, no agentic frameworks, no tool use.
Recently I’ve been auditing ksmbd for vulnerabilities. ksmbd is “a linux kernel server which implements SMB3 protocol in kernel space for sharing files over network.“. I started this project specifically to take a break from LLM-related tool development but after the release of o3 I couldn’t resist using the bugs I had found in ksmbd as a quick benchmark of o3’s capabilities. In a future post I’ll discuss o3’s performance across all of those bugs, but here we’ll focus on how o3 found a zeroday vulnerability during my benchmarking. The vulnerability it found is CVE-2025-37899 (fix here), a use-after-free in the handler for the SMB ‘logoff’ command. Understanding the vulnerability requires reasoning about concurrent connections to the server, and how they may share various objects in specific circumstances. o3 was able to comprehend this and spot a location where a particular object that is not referenced counted is freed while still being accessible by another thread. As far as I’m aware, this is the first public discussion of a vulnerability of that nature being found by a LLM.
Before I get into the technical details, the main takeaway from this post is this: with o3 LLMs have made a leap forward in their ability to reason about code, and if you work in vulnerability research you should start paying close attention. If you’re an expert-level vulnerability researcher or exploit developer the machines aren’t about to replace you. In fact, it is quite the opposite: they are now at a stage where they can make you significantly more efficient and effective. If you have a problem that can be represented in fewer than 10k lines of code there is a reasonable chance o3 can either solve it, or help you solve it.
Benchmarking o3 using CVE-2025-37778
Lets first discuss CVE-2025-37778, a vulnerability that I found manually and which I was using as a benchmark for o3’s capabilities when it found the zeroday, CVE-2025-37899.
CVE-2025-37778 is a use-after-free vulnerability. The issue occurs during the Kerberos authentication path when handling a “session setup” request from a remote client. To save us referring to CVE numbers, I will refer to this vulnerability as the “kerberos authentication vulnerability“.
If krb5_authenticate detects that the session state is SMB2_SESSION_VALID then it frees sess->user. The assumption here appears to be that afterwards either ksmbd_krb5_authenticate will reinitialise it to a new valid value, or that after returning from krb5_authenticate with a return value of -EINVAL that sess->user will not be used elsewhere. As it turns out, this assumption is false. We can force ksmbd_krb5_authenticate to not reinitialise sess->user, and we can access sess->user even if krb5_authenticate returns -EINVAL.
This vulnerability is a nice benchmark for LLM capabilities as:
It is interesting by virtue of being part of the remote attack surface of the Linux kernel.
It is not trivial as it requires:
(a) Figuring out how to get sess->state == SMB2_SESSION_VALID in order to trigger the free.
(b) Realising that there are paths in ksmbd_krb5_authenticate that do not reinitialise sess->user and reasoning about how to trigger those paths.
(c) Realising that there are other parts of the codebase that could potentially access sess->user after it has been freed.
While it is not trivial, it is also not insanely complicated. I could walk a colleague through the entire code-path in 10 minutes, and you don’t really need to understand a lot of auxiliary information about the Linux kernel, the SMB protocol, or the remainder of ksmbd, outside of connection handling and session setup code. I calculated how much code you would need to read at a minimum if you read every ksmbd function called along the path from a packet arriving to the ksmbd module to the vulnerability being triggered, and it works out at about 3.3k LoC.
OK, so we have the vulnerability we want to use for evaluation, now what code do we show the LLM to see if it can find it? My goal here is to evaluate how o3 would perform were it the backend for a hypothetical vulnerability detection system, so we need to ensure we have clarity on how such a system would generate queries to the LLM. In other words, it is no good arbitrary selecting functions to give to the LLM to look at if we can’t clearly describe how an automated system would select those functions. The ideal use of an LLM is we give it all the code from a repository, it ingests it and spits out results. However, due to context window limitations and regressions in performance that occur as the amount of context increases, this isn’t practically possible right now.
Instead, I thought one possible way that an automated tool could generate context for the LLM was through expansion of each SMB command handler individually. So, I gave the LLM the code for the ‘session setup’ command handler, including the code for all functions it calls, and so on, up to a call depth of 3 (this being the depth required to include all of the code necessary to reason about the vulnerability). I also include all of the code for the functions that read data off the wire, parses an incoming request, selects the command handler to run, and then tears down the connection after the handler has completed. Without this the LLM would have to guess at how various data structures were set up and that would lead to more false positives. In the end, this comes out at about 3.3k LoC (~27k tokens), and gives us a benchmark we can use to contrast o3 with prior models. If you’re interested, the code to be analysed is here as a single file, created with the files-to-prompt tool.
The final decision is what prompt to use. You can find the system prompt and the other information I provided to the LLM in the .prompt files in this Github repository. The main points to note are:
I told the LLM to look for use-after-free vulnerabilities.
I gave it a brief, high level overview of what ksmbd is, its architecture, and what its threat model is.
I tried to strongly guide it to not report false positives, and to favour not reporting any bugs over reporting false positives. I have no idea if this helps, but I’d like it to help, so here we are. In fact my entire system prompt is speculative in that I haven’t ran a sufficient number of evaluations to determine if it helps or hinders, so consider it equivalent to me saying a prayer, rather than anything resembling science or engineering. Once I have ran those evaluations I’ll let you know.
To run the query I then use the llm tool (github) like:
My experiment harness executes this N times (N=100 for this particular experiment) and saves the results. It’s worth noting, if you rerun this you may not get identical results to me as between running the original experiment and writing this blog post I had removed the file containing the code to be analysed, and had to regenerate it. I believe it is effectively identical, but have not re-run the experiment.
o3 finds the kerberos authentication vulnerability in the benchmark in 8 of the 100 runs. In another 66 of the runs o3 concludes there is no bug present in the code (false negatives), and the remaining 28 reports are false positives. For comparison, Claude Sonnet 3.7 finds it 3 out of 100 runs and Claude Sonnet 3.5 does not find it in 100 runs.So on this benchmark at least we have a 2x-3x improvement in o3 over Claude Sonnet 3.7.
For the curious, I have uploaded a sample report from o3 (here) and Sonnet 3.7 (here). One aspect I found interesting is their presentation of results. With o3 you get something that feels like a human-written bug report, condensed to just present the findings, whereas with Sonnet 3.7 you get something like a stream of thought, or a work log. There are pros and cons to both. o3’s output is typically easier to follow due to its structure and focus. On the other hand, sometimes it is too brief, and clarity suffers.
o3 finds a 0-day (CVE-2025-37899)
Having confirmed that o3 can find the kerberos authentication vulnerability (CVE-2025-37778) when given the code for the session setup command handler, I wanted to see if it could find it if I give it the code for all of the command handlers. This is a harder problem as the command handlers are all found in smb2pdu.c, which has ~9k LoC. However, if o3 can still find vulnerabilities when given all of the handlers in one go then it suggests we can build a more straightforward wrapper for o3 that simply hands it entire files, covering a variety of functionality, rather than going handler by handler.
Combining the code for all of the handlers with the connection setup and teardown code, as well as the command handler dispatch routines, ends up at about 12k LoC (~100k input tokens), and as before I ran the experiment 100 times.
o3 finds the kerberos authentication vulnerability in 1 out of 100 runs with this larger number of input tokens, so a clear drop in performance, but it does still find it. More interestingly however, in the output from the other runs I found a report for a similar, but novel, vulnerability that I did not previously know about. This vulnerability is also due to a free of sess->user, but this time in the session logoff handler.
Short description ================= While one ksmbd worker thread is still executing requests that use sess‑>user, another thread that processes an SMB2 LOGOFF for the same session frees that structure. No synchronisation protects the pointer, so the first thread dereferences freed memory – a classic use‑after‑free that leads to kernel memory corruption and arbitrary code execution in kernel context.
Affected code path ------------------ 1. A second transport is bound to an existing session (SMB 3.0 or later, `conn->binding == true`).
2. Worker‑A (running on connection C2) receives any normal request (e.g. WRITE). • `smb2_check_user_session()` stores a pointer to the already existing `struct ksmbd_session` in `work->sess` and increments the session ref‑count, **but it does not take any reference on `sess->user`.** • The pointer to `sess` is kept for the whole request processing; every helper that needs authentication data accesses `sess->user` directly.
3. Before Worker‑A finishes, Worker‑B (running on the first connection C1) processes an SMB2 LOGOFF for the same session and executes `smb2_session_logoff()` (smb2pdu.c).
Relevant part of smb2_session_logoff() --------------------------------------
```c ... if (sess->user) { ksmbd_free_user(sess->user); /* (1) frees memory */ sess->user = NULL; /* (2) clear the field */ } ... ```
`ksmbd_free_user()` ultimately ends in simple `kfree(user)`.
4. Worker‑B **does not wait for the other connections that are still using the session**; it only waits for running requests on *its own* connection (`ksmbd_conn_wait_idle(conn)`).
5. Worker‑A continues to execute (e.g. inside `smb2_open()`, `smb2_write()`, …) and dereferences `sess->user`:
```c /* examples (many of them) */ if (user_guest(sess->user)) ← dereference after free ksmbd_compare_user(sess->user, …) sess->user->uid ```
Because the memory was already `kfree()`‑ed in step (1) the access is to freed memory. Depending on exact timing it is either:
• a use‑after‑free (pointer still points into now‑reused slab object), enabling controlled kernel‑memory overwrite, or • a NULL–deref (if Worker‑A reads after step (2)), still a DoS.
Reading this report I felt my expectations shift on how helpful AI tools are going to be in vulnerability research. If we were to never progress beyond what o3 can do right now, it would still make sense for everyone working in VR to figure out what parts of their work-flow will benefit from it, and to build the tooling to wire it in. Of course, part of that wiring will be figuring out how to deal with the the signal to noise ratio of ~1:50 in this case, but that’s something we are already making progress at.
One other interesting point of note is that when I found the kerberos authentication vulnerability the fix I proposed was as follows:
When I read o3’s bug report above I realised this was insufficient. The logoff handler already sets sess->user = NULL, but is still vulnerable as the SMB protocol allows two different connections to “bind” to the same session and there is nothing on the kerberos authentication path to prevent another thread making use of sess->user in the short window after it has been freed and before it has been set to NULL. I had already made use of this property to hit a prior vulnerability in ksmbd but I didn’t think of it when considering the kerberos authentication vulnerability.
Having realised this, I went again through o3’s results from searching for the kerberos authentication vulnerability and noticed that in some of its reports it had made the same error as me, in others it had not, and it had realised that setting sess->user = NULL was insufficient to fix the issue due to the possibilities offered by session binding. That is quite cool as it means that had I used o3 to find and fix the original vulnerability I would have, in theory, done a better job than without it. I say ‘in theory’ because right now the false positive to true positive ratio is probably too high to definitely say I would have gone through each report from o3 with the diligence required to spot its solution. Still, that ratio is only going to get better.
Conclusion
LLMs exist at a point in the capability space of program analysis techniques that is far closer to humans than anything else we have seen. Considering the attributes of creativity, flexibility, and generality, LLMs are far more similar to a human code auditor than they are to symbolic execution, abstract interpretation or fuzzing. Since GPT-4 there has been hints of the potential for LLMs in vulnerability research, but the results on real problems have never quite lived up to the hope or the hype. That has changed with o3, and we have a model that can do well enough at code reasoning, Q&A, programming and problem solving that it can genuinely enhance human performance at vulnerability research.
o3 is not infallible. Far from it. There’s still a substantial chance it will generate nonsensical results and frustrate you. What is different, is that for the first time the chance of getting correct results is sufficiently high that it is worth your time and and your effort to try to use it on real problems.
A few months back I wrote a blog post where I mentioned that the least-effort/highest reward approach to application optimisation is to deploy a whole-system profiler across your clusters, look at the most expensive libraries & processes, and then search Google for faster, equivalent replacements. At Optimyze/Elastic we have had customers of our whole-system profiler use this approach successfully on numerous occasions. The only difficulty with this approach is the amount of Googling for alternatives that you need to do, followed by even more Googling for comparative benchmarks. If only we had a compressed version of all information on the internet, and an interface that allowed for production of free-form text based on that!
As you’ve probably gathered: we do. OpenAI’s, and other’s, Large Language Models (LLMs), have been trained on a huge amount of the internet, including the blurbs describing a significant number of available software libraries, as well as benchmarks comparing them, and plenty of other relevant content in the form of blogs, StackOverflow comments, and Github content.
So why use an LLM as a search interface when you could just Google for the same information? There are a couple of reasons. The first is that an LLM provides a much broader set of capabilities than just search. You can, for example, ask something like “Find me three alternative libraries, list the pros and cons of each, and then based on these pros and cons make a recommendation as to which I should use.”. Thus, we can condense the multistep process of Googling for software and benchmarks, interpreting the results, and coming up with a recommendation, into a single step. The second reason is that because LLMs have a natural language input/output interface, it is far easier to programatically solve the problem and make use of the result than if we had to use Google’s API, scrape web pages, extract information, and then produce a report.
If you’d like to try this out, a couple of days ago I open sourced sysgrok (blog, code), a tool intended to help with automating solutions to systems analysis and understanding. It is organised into a series of subcommands, one of which is called findfaster. The findfaster subcommand uses a prompt that asks the question mentioned above. Here’s an example of using it to find a faster replacement for libjpeg.
sysgrok also has a “–chat” parameter which will drop you into a chat session with the LLM after it has produced an initial response. This can be used to ask for clarification on recommendations, correct mistakes the LLM has made etc. For example, here we ask for replacements for Python’s stdlib JSON library. The LLM responds with three good alternatives (ujson, orjson, simdjson), and recommends we use the best of them (orjson). We then drop into a chat session and ask the LLM how to install and use the library.
Usually this works really well, and is the best automated solution to this problem that I have come across. That said, we are using an LLM, so it can go amusingly wrong at times. The most common way for it to fail is the wholesale hallucination of software projects. This is prone to happening when there are limited, or no, alternatives to the target software which provide the same functionality but better performance. A good example of this is libtiff. If you ask findfaster to find you a faster version of libtiff you’ll may be used to consider TurboTiff. TurboTiff is not a software project.
If you use sysgrok and it comes back with a bad recommendation then I’d love to hear about it, as these examples are helpful in refining the prompts. You can open an issue on GitHub here.
In the previous post I advocated for building systems that combine static and dynamic analysis for performance optimisation. By doing so, we can build tools that are much more useful than those focused on either analysis approach alone. In fact, for many static analyses it’s likely that the difference between being useful at all and not so, is whether or not it’s combined with a profiler. As an example, continuous profiling can gather information on the hottest code paths in production environments, and this can be used to rank the output of the static analysis. A developer can then focus their efforts on the most important findings. This minimises the time wasted due to false positives, or unimportant true positives, from the static analysis. Conversely, static analysis can be used to provide further context on the output of continuous profiling and make its results more actionable, such as suggesting why a particular function may be hot, or suggesting potential optimisations.
In the previous post also I outlined a trivial-but-very-effective combination of analyses, in which the Top N most expensive functions identified by continuous profiling are piped into a service that checks library and function names against a list of known faster replacements, allowing a developer to optimize their application with zero code changes. e.g. swapping jemalloc for libc malloc, zlib-ng for zlib, orjson for Python’s stdlib JSON etc.
In this post we’re going to go deeper, with a static analysis that actually looks at the application’s code. When I started thinking about combinations of analyses for performance optimisation, I didn’t find much in the way of off-the-shelf static analyses that I could just use. So, I decided to build my own. We’re going to try and answer the question: can we use static analysis to find C/C++ code patterns that lead to sub-optimal machine code being emitted by the compiler?
I’ll first describe a particular code pattern that can lead to the compiler emitting unnecessary memory reads, and failing to auto-vectorise loops. When these patterns exist they can lead to functions being 10-20x or more slower than they otherwise could be. I’ll show how we can build CodeQL queries to find the patterns, and how we can modify the code to allow the compiler to auto-vectorise. I’ll then discuss results of applying the queries to a few code bases, lay out some issues that arise, and detail some potential future work and open questions.
CodeQL
CodeQL allows you to write queries in a declarative object-oriented language, and apply those queries to a codebase that has been converted into a relational representation in a database. In other words, it provides a relatively easy-to-work-with query language for finding interesting patterns in code. Typically it is used in the security space for bug hunting. From a vulnerability hunter’s point of view CodeQL provides a relatively unique and powerful capability for a static analysis tool. Existing static analysis tools (Coverity, the clang static analyser etc.) encode checks for common vulnerability patterns, but by virtue of the fact that these very tools are part of the toolbox of many software developers, and the fact that trivial overflow patterns are less and less likely to make it through modern QA, such analysers aren’t particularly helpful for a vulnerability hunter. For this reason, and others, static analysis by and large does not have a great reputation amongst people interested in finding exploitable software flaws. By allowing one to conveniently encode arbitrary patterns and search for them in a database, CodeQL enables “variant analysis”, i.e. searching for variations of a given bug in the same codebase, or a new codebase. This turns out to be a fruitful way of finding security vulnerabilities. As of yet CodeQL hasn’t seen any use that I’m aware of in the realm of detecting performance issues, but its flexibility makes it an excellent candidate technology for any property that can be encoded as predicates over an abstract syntax tree.
The Inconveniences of Type Aliasing in C/C++
In Optimising an eBPF Optimiser with eBPF I discussed searching for performance improvements in a program synthesis engine. One of the optimisations I made was to modify the code to allow the compiler to auto-vectorise a series of very hot loops which looked as follows:
Under the hood, a std::vector<bool> has some properties that mean the loops cannot be auto-vectorised. See the post I just mentioned for details, but in short: we needed to replace std::vector<bool> with a vector of something other than a bool. The original something that I chose was a uint8_t but, to my surprise, instead of getting out a nicely unrolled and vectorised loop, what I got was this:
The compiler has generated code that on each iteration of the loop loads the source and destination pointers from [r12] and [rbx+0xa8], and thus it cannot auto-vectorise. I eventually tracked down the issue with the help of this post by Travis Downs. The problem is type aliasing. In C/C++, the char type (and its kin, such as uint8_t) can alias every other type. On a write to memory through such a type the compiler has to assume that it may have modified any other heap-based memory location, even if that location has an entirely different type (such as the data pointers contained in the source and destination vectors in the above example). Because of this, in the above example, the compiler must assume [r12] and [rbx+0xa8] could have been modified by the write to [rdx+rax] and therefore cannot safely auto-vectorise the loop as it needs to reload these values after each write.
In many situations, having to reload a value from memory is not the end of the world, but in the context of loops in particular the issue can lead to drastically worse code being generated by the compiler than would otherwise be possible. In Travis’ blog post he shows a particularly pathological example where the issue leads to code that is 20x slower than it could be.
There are a variety of ways to fix this ‘problem’. Where possible, replacing the uint8_t/char type with a char8_t will solve it. The char8_t type, introduced in C++20, does not have the aliasing issue that char does. If C++20 cannot be used, and switching to some other wider primitive type is not reasonable, then another option is to try and lift any code that requires a load from memory out of the loop. For simple code this can be straightforward e.g. lifting an access to the size() attribute of a vector out of the loop condition, to before the loop. However, for larger, more complex loops, this can quickly become infeasible and one can be stuck with accepting the overhead of unnecessary memory loads due to type aliasing.
Searching for Aliasing Writes
Our goal is to build a query that will find patterns in code whereby, due to writes through aliasing types, the compiler is generating loads from memory that we know are unnecessary. Lets begin by describing at a high level what we are looking for.
What we want to search for a sequence of code which looks like:
A load from memory through an expression X, where X denotes a memory location. e.g. X may be of the form *a, a[i], *(a+i) etc.
Followed by a write through an aliasing type, such as a char
Followed by a load from memory through X, such that none of the components of the expression X have been modified since step (1). e.g. if the expression X is *(arr+i) then we require that both arr and i have not been modified. If they have been modified then the compiler would need to emit another load from memory, regardless of the write through the aliasing type.
At a glance, this seems like a fairly easy set of properties for a static analyser to match on. We won’t worry about reasoning across function boundaries (although we will handle inlined functions), and each property can be expressed as a syntactic predicate on an AST.
In the following examples the code marked as [1], [2], and [3] correspond to items 1, 2 and 3 in the above list.
The above pattern will match a straight-line sequence like the following:
Here [1] marks the first load from memory via the the read of gstring->len, [2] marks the write through the aliasing type via the write of c into gstring->str, and [3] marks the second read via the read of gstring->len again. Due to [2] the compiler is forced to generate a second load of gstring->len at [3] although we can see that the write at [2] cannot impact it, and the value could have been stored in a register and reused . In fact, the write through the aliasing type results in two extra reads from memory here, as on part [3] the compiler not only has to reload gstring->len but also gstring->str. You can view the assembly produced for this on Compiler Explorer.
The pattern will also match slightly more complex loops such as:
// tesseract/src/classify/adaptmatch.cpp
for (unsigned id = 0; id < templates->NumClasses; ++id) { // 1,3
int font_set_id = templates->Class[id]->font_set_id;
const FontSet &fs = fontset_table_.at(font_set_id);
for (auto f : fs) {
const Shape &shape = shape_table_->GetShape(f);
for (int c = 0; c < shape.size(); ++c) {
if (char_norm_array[shape[c].unichar_id] < pruner_array[id]) {
pruner_array[id] = char_norm_array[shape[c].unichar_id]; // 2
}
}
}
}
(Here [1] and [3] mark the first and second loads of templates->NumClasses, while [2] marks the write to pruner_array which has type uint8_t*. There are actually several other values that must be reloaded from memory in this example due to the aliasing write, not just templates->NumClasses.)
The pattern we have described matches not just the outermost loop above, but also the innermost loop on line 7, as shape is a vector and the call to the size() function will be inlined.
// tesseract/src/classify/adaptmatch.cpp
for (int c = 0; c < shape.size(); ++c) { // 1,3
if (char_norm_array[shape[c].unichar_id] < pruner_array[id]) {
pruner_array[id] = char_norm_array[shape[c].unichar_id]; // 2
}
On each iteration of the loop the size of the vector will be unnecessarily reloaded due to the write at [2].
To bring these examples full circle, lets actually make the change required to remove the aliasing issue. Jumping back to the glib example, the original version can be found on Compiler Explorer here and the optimised version (in which we replace the char type with the C++20 char8_t type) can be found here. Below, the original is on the left, and the version using char8_t is on the right.
In the original, lines 79 to 81 correspond to gstring->str[gstring->len] = 0. The rdi register points to the GString structure, with the pointer to the string at offset 0 and the length at offset 8. We can see that the compiler has emitted code to load both from memory due to the write on line 78 which it must consider as potentially aliasing with the internals of the GString object. In the optimised version using char8_t we can see that the compiler has not had to worry about the aliasing write, and has generated a single instruction for this line of code: line 78. This instruction reuses the string pointer and string length which were previously loaded into rcx and rax.
In conclusion, we have a pattern we can describe in plain English to find a code pattern, and we have evidence that if we can find such a code pattern then we can make trivial changes that may enable the compiler to emit more efficient code. Lets now move onto building CodeQL queries to automate the search for this pattern.
CodeQL Queries to Find Aliasing Writes
What we are searching for is conceptually very simple: two loads from memory, with a write through an aliasing type in between. The easiest part of this to express in CodeQL is the write, which looks as follows (I’ve put all the CodeQL queries we’ll build in this repository, and this sample can be found here):
predicate isMemCharWriteExpr(Expr e) {
exists(AssignExpr a, Expr lval |
a = e.(AssignExpr) and // A
lval = a.getLValue() and
lval.getType().stripType() instanceof CharType and // B
(
lval instanceof PointerDereferenceExpr or // C
lval instanceof ArrayExpr or // C
lval instanceof OverloadedArrayExpr // C
)
)
}
This predicate returns true if the expression passed to it matches “an assignment expression (A), in which the lvalue has a character type (B) and the lvalue is a pointer dereference, array expression or overloaded array expression (C)”. We can immediately see here that expressing an assembly level concept like “a read from memory” requires us to enumerate the C/C++-level syntactic constructs that we think may produce such assembly. This has the potential to introduce both false positives and false negatives. It will also result in our queries being quite verbose, even though in natural language we can concisely express the properties we want to match on.
The increment and decrement operators can also result in a write to memory, (e.g. v[x]++), so our predicate must also account for those. They can be handled in a similar manner to assign expressions, so for brevity I have not presented that part of the query here, but you can find the full predicate here on Github.
We next need a way to match against C/C++ code that we think will produce loads from memory with the properties that we outlined as item 1 and item 3 in the sequence that we are after. For this, we need to construct a query which matches two expressions in the same function that will result in a load from memory, where in theory the compiler could cache the result of the first load in a register and reuse it in the second load, if it weren’t for the intervening write through the aliasing type. There are a few different syntactic constructs in C that may result in a load from memory. We could have:
An array expression, e.g. x = array[offset]
A pointer dereference, e.g. x = *ptr
A pointer field access, e.g. x = ptr->val
Alongside these we also have the possibility that functions that result in memory reads can be inlined, e.g. the vector size() function.
The query implementation for finding code patterns that involve array expressions, pointer dereferences and pointer field accesses are all fairly similar, so I will just walk through the one for pointer field accesses here (found here on Github, with the helper functions here). A pointer field access consists of something like base->field. In the following code, a1 represents our first memory access, w represents the write to memory through the character type, and a2 represents our second memory access.
from
Expr w, PointerFieldAccess a1, PointerFieldAccess a2, Variable baseVar
where
(
isMemCharWriteExpr(w) and // [1]
// Sequence of execution is a1 -> w -> a2
a1 = w.getAPredecessor+() and // [2]
w = a2.getAPredecessor+() and // [2]
baseVar = a1.getQualifier().(VariableAccess).getTarget() and // [3]
// Assert that a1 and a2 use the same base pointer
baseVar = a2.getQualifier().(VariableAccess).getTarget() and // [3]
// Assert a1 and a2 access the same field in the struct
a1.getTarget() = a2.getTarget() and // [4]
// Eliminate cases where the variable holding the base pointer is modified
not exists(AssignExpr redef | // [5]
redef = a1.getASuccessor+()
and redef = a2.getAPredecessor+()
and redef.(AssignExpr).getLValue().(VariableAccess).getTarget() = baseVar
)
// Further cases here to eliminate things like increments, redeclarations etc
...
)
select a1.getLocation().getFile().getBaseName(), a1.getLocation().getStartLine(), a1, w, a2, baseVar
We begin by passing the write expression w to our predicate to assert that it is a write of a character type that will result in a memory dereference
We then assert the ordering of our three expressions, namely that a1 comes before w which comes before a2
We need to get the base variable from base->ptr so we can later make assertions on it. We extract it from a1 and assign it to baseVar, and then also assert that a2 makes use of the same base variable. While this might look like we are assigning something to baseVar and then immediately overwriting it, remember that this is a declarative query language, not an imperative one. We are stating that baseVar equals two things, therefore they must be the same.
We also need to assert that the field accessed is the same at a1 and a2
Finally, we specify that between a1 and a2 the baseVar has not been modified. The case above specifies that there are no assignment expressions between a1 and a2 where the lvalue is the base variable. In the full query we also handle a few other ways that the base variable might be modified.
And that’s it! This query, and the similar ones for pointer dereferences and array expressions, are sufficient to find the patterns we’re looking for. It will find them in both straight-line sequences of code and in loops. As presented, these queries operate in a scope that is local to a single function. They won’t find cases where the memory access results from a call to an inlined function, such as vector.size(). In the next section I’ll show how we can deal with that scenario, as it is necessary in order to detect inlined function calls in loop conditions, which is a productive source of the sorts of memory accesses we are searching for.
Finding Inlined Memory Accesses in Loop Conditions
A common source of memory loads that meet our requirements are loads behind an inlined function call in a loop condition, e.g. something that checks the size of a vector, such as for (i = 0; i < vector.size(); i++). We could modify our existing queries that search for two memory accesses with an intervening aliasing write, as they are generalisations of the case of a loop condition containing a memory access and an aliasing write within that loop body. However, one lesson I’ve learned with CodeQL is that it’s often easier to build queries for exactly what you have in mind and later generalise if necessary. Premature generalisation can lead to overly complex queries that are difficult to debug, and prone to both false positives and false negatives. Starting with a concrete example, then generalising if necessary, has generally proven to be a better strategy.
A concrete example of what we wish to find is:
void vector8_inc(std::vector<uint8_t> &v) {
for (size_t i = 0; i < v.size(); i++) {
v[i]++;
}
}
So, we want a loop in which:
The condition has a call to an inlined function that results in a memory access, and
There is a write to memory within the body of the loop.
The CodeQL query to express this begins as follows:
from Loop l, Expr w
where
// The loop condition accesses memory in some way
loopConditionAccessesMemory(l)
// And the loop contains a character-write expression
and isMemCharWriteExpr(w) // [1]
and w.getEnclosingStmt().getParentStmt*() = l.getStmt() // [2]
select l.getLocation().getFile().getBaseName(), l.getLocation().getStartLine(), l, w
The write-to-memory part is handled in the same manner as our earlier queries via isMemCharWriteExpr [1], and we add the requirement that the write expression is inside the loop [2]. loopConditionAccessesMemory is the predicate we’ll use to find loop conditions that either access memory directly or call an inlined function that does so (the query contents found here, with most of the functionality in helpers found here on GitHub). It looks as follows:
// Returns true if the loop condition contains a function call that we think will
// result in a memory access.
predicate loopConditionAccessesMemory(Loop l) {
exists(FunctionCall funcCall, Function func |
funcCall = l.getCondition().getAChild() // [1]
and func = funcCall.getTarget()
and func.isInline() // [2]
and allCalleesAreInline(func) // [3]
and hasMemoryAccess(func) // [4]
)
}
We want a loop condition containing a function call [1] to an inline function [2] that itself only calls other inline functions [3] and that either it, or its callees, contain a memory access [4]. The predicates that check [3] and [4] are recursive, and look as follows:
// Recursive predicate. Returns true if all functions called from this function
// are inline, as are their callees, and so on.
predicate allCalleesAreInline(Function func) {
not exists (Function called | // [1]
(not called.isInline() or not allCalleesAreInline(called)) // [2]
and called.getACallToThisFunction().getEnclosingFunction() = func // [3]
)
}
allCalleesAreInline asserts that there are no functions [1] that are called from the current function [3], such that the called function is not inline or it calls any functions that are not inline [2].
// Recursive predicate. Returns true if this function, or any function it calls,
// contains an expression that we think will result in a memory access.
predicate hasMemoryAccess(Function func) {
// The function contains either a PointerFieldAccess (e.g. this->x) or an
// implicit access via the this pointer
exists (PointerFieldAccess pfa | pfa.getEnclosingFunction() = func) // [1]
or exists (ImplicitThisFieldAccess itfa | itfa.getEnclosingFunction() = func) // [1]
// Or, it calls a function that meets the above properties
or exists (Function called | // [2]
called.getACallToThisFunction().getEnclosingFunction() = func
and hasMemoryAccess(called))
}
hasMemoryAccess asserts that this function contains an expression that may produce a memory access [1], or that it calls a function that contains a memory access [2].
Alternatively, instead of building the predictaes to look for any inline function with memory accesses, we could have gone with a more hacky variant and matched specifically on calls to functions with names like “size”, “length” and whatever other functions we think might have the properties that we want. In fact, I did this in the first version of the query, and it does work, with one important caveat. For the curious, that predicate looked as follows:
// Find a loop with a call to vector.size() (or some equivalent) in the condition
predicate loopConditionAccessesMemory(Loop loopCond) {
exists(Expr funcCall, Function func, string fname |
funcCall = loopCond.getCondition().getAChild()
and funcCall instanceof FunctionCall
and func = funcCall.(FunctionCall).getTarget()
and func.isInline()
and fname = func.getName()
and (
fname = "size" or fname = "len" or fname = "count" or fname = "length"
or fname = "begin" or fname = "end" or fname = "rbegin" or fname = "rend"
)
)
}
While functional, this may result in false negatives when we fail to predict the custom function names used in a particular project. In C++ codebases, custom inlined accessor functions that appear in loop bounds are quite common. E.g. the get_height function in the following loop header is found by the more complex predicate I showed above, but not by the simplified one that just matches on function names.
for (uint32_t y = 0; y < img.get_height(); y++)
Results & Analysis
In order to run CodeQL queries on a project you need a CodeQL database. Such databases are automatically built for public projects on Github and then hosted on lgtm.com. I picked a few C++ projects from there with the goal of answering the following questions:
Do the queries work at all? With static analysis I’m always mildly afraid that when applied to real world projects I’ll either be drowned in false positives or get no results at all due to an analyser either dying or running forever. So, first I wanted to see if I can actually get a result set in a reasonable amount of time, with a reasonable false positive to true positive ratio.
For the true positives, can we optimise the code so that the aliasing write is either removed or the code is restructured so that its impact is limited. If so, what sort of performance improvement do we get as a result?
How, if at all, would this analysis fit into a real development workflow or CI/CD pipeline?
Let’s first start with some concrete examples of true positives found by the analysis.
Sample Findings
Bitcoin
The codebase I started with was bitcoin. The queries to find accesses resulting from pointer dereference expressions (PDE) and pointer field accesses (PFA) mostly turned up false positives. There were a few true positives, but they were in straight-line sequences of code and the sort of thing where even if the aliasing write was removed it might save on a single memory access on each function invocation. So, not something I wanted to even consider looking into unless we were really desperate for results! Meanwhile, the Array Expression (AE) query turned up no results at all. Maybe we would end up desperate after all 😉
However, the query searching for memory accesses in loop conditions (LC) came to the rescue finding a bunch of interesting true positives. I’ll get into more detail in the analysis at the end of the post, but to answer any of you wondering “Why was the LC query successful when the others were not?”, empirically it turns out the sweet spot for this sort of analysis is code that has two properties:
It’s a loop, meaning any redundant memory accesses we remove will be saved on every loop iteration, and not just once.
The loop condition accesses some class attribute, meaning at least one redundant access will be emitted in order to load that value. This access is often behind an inlined function, which the LC query will handle correctly, while the others do not.
Onto the findings …
bech32.cpp bech32::ExpandHRP
The bech32::ExpandHRP function is found in src/bech32.cpp.
/** Expand a HRP for use in checksum computation. */
data ExpandHRP(const std::string& hrp)
{
data ret;
ret.reserve(hrp.size() + 90);
ret.resize(hrp.size() * 2 + 1);
for (size_t i = 0; i < hrp.size(); ++i) { // 1
unsigned char c = hrp[i];
ret[i] = c >> 5; // 2
ret[i + hrp.size() + 1] = c & 0x1f; // 2
}
ret[hrp.size()] = 0;
return ret;
}
At [1] we have a call to the size() function of std::string, which will read the length of the string from memory. Then at [2] we have two writes to the memory that is backing the ret variable. ret has the data type, which is just a typedef for std::vector<uint8_t>. While ret itself lives on the stack, the call to reserve will result in a call to new which will allocate space on the heap for its contents. If this were not the case, and the contents remained on the stack then the aliasing write would not be a problem as the compiler could safely assume that the writes to the vector on the stack would not interfere with the contents of hrp. However, due to the reallocation on the heap and the fact that the uint8_t is essentially a char, the compiler must assume that at [2] the writes may update the length of the string hrp. It will therefore generate code to load that value from memory at the head of the loop on each iteration.
It gets worse. To see why, lets look at the assembly generated.
The copy loop generated by clang 13.0.1 (-O3 -march=skylake -std=c++20) is as follows (you can find it on Compiler Explorer here):
.LBB0_15:
mov rcx, qword ptr [rbx] // A. Load the string contents pointer from hrp
movzx ecx, byte ptr [rcx + rax] // B. Load next byte from the string
mov edx, ecx
shr dl, 5
mov rsi, qword ptr [r14] // C. Load the vector contents pointer from ret
mov byte ptr [rsi + rax], dl // D. Write ‘c >> 5’ to vector contents
and cl, 31
mov rdx, qword ptr [r14] // E. Load the vector contents pointer from ret
add rdx, qword ptr [rbx + 8] // F. Add hrp.size() to contents pointer
mov byte ptr [rax + rdx + 1], cl // G. Write ‘c & 0xff’ to vector contents
inc rax
mov rcx, qword ptr [rbx + 8] // H. Check ‘i < hrp.size()’
cmp rax, rcx
jb .LBB0_15
Both the string variable hrp and the vector variable ret contain data pointers which refer to their contents, and even though we know that these pointers in hrp and ret cannot change due to the writes performed in the loop (nor can the length of hrp) the compiler has to generate loads for these pointers (and the length) after each write to ret. The redundancy is most obvious at [E] where, due to the write at [D], the compiler is forced to reload the value from ret (*r14) that it had just loaded at [C].
You may be wondering why the compiler is forced to reload the pointer from ret at all, even in the presence of the aliasing write, given that ret itself is stack allocated and should be provably distinct from the writes to the heap. The answer can be found by looking at the link to Compiler Explorer above. Due to C++’s Return Value Optimisation/Copy Elision, the pointer to be used for ret is passed to ExpandHRP by the caller in the rdi register, then moved to r14, rather than being stack allocated and then copied out upon the return. See here for more details. While normally a good thing, this has the downside in this case that the compiler can no longer assume that the writes do not alias with the memory that backs ret.
In summary, we end up with 6 loads from memory on each iteration of the loop, when in reality we need just the one to load the byte of data we wish to operate on. The necessity of these loads also means that the compiler is prevented from vectorising the loop. If the pointers and size were guaranteed to be stable during iteration of the loop then it could copy large chunks of data, instead of single bytes at a time. But it can’t.
So how do we fix it?
Turns out it’s fairly straightforward: define data as a std::vector<char8_t> (C++20 only) instead of std::vector<uint8_t>, thus eliminating the aliasing issue. The compiler no longer needs to reload data pointers or the source string size, and all going well we should get a nicely vectorised loop. The Compiler Explorer result is here and is as expected.
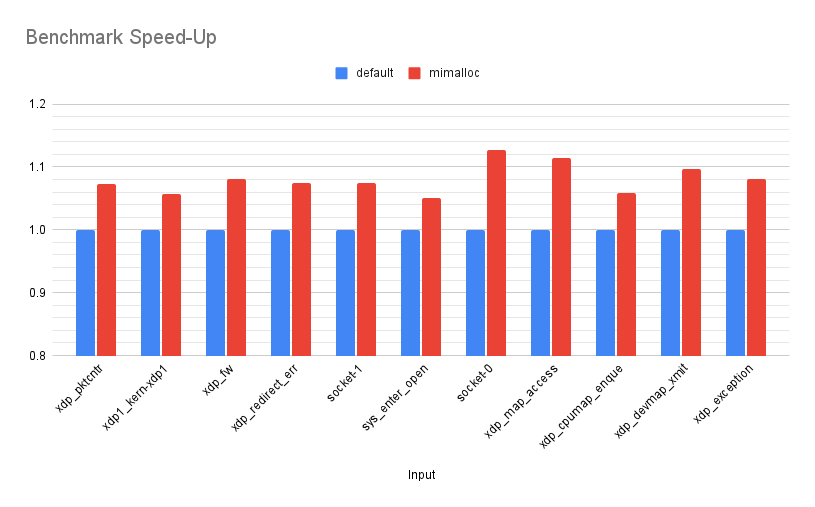
The following graph shows the benchmark results for the original versus the optimised example, and varying the input size.
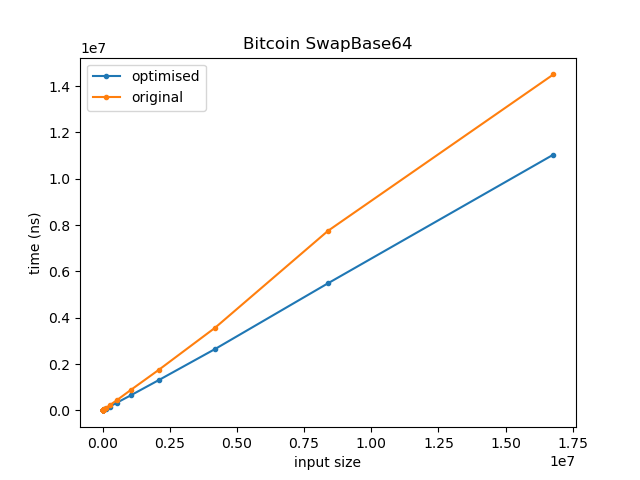
Not bad for a four character change! At 32k input bytes the optimised version is 12x faster than the previous version! In practice, it seems the maximum input length that can reach ExpandHRP in the bitcoin codebase is 90. At this size the optimised version is 2.6x faster, so still quite a nice improvement.
i2p.cpp SwapBase64
Another result from bitcoin is found in src/i2p.cpp. The SwapBase64 function looks as follows:
std::string orig_SwapBase64(const std::string& from)
{
std::string to;
to.resize(from.size());
for (size_t i = 0; i < from.size(); ++i) { // 1
switch (from[i]) {
case '-':
to[i] = '+'; // 2
break;
case '~':
to[i] = '/'; // 2
break;
case '+':
to[i] = '-'; // 2
break;
case '/':
to[i] = '~'; // 2
break;
default:
to[i] = from[i]; // 2
break;
}
}
return to;
}
As before we have a loop in which the size of a string is used in the loop condition [1] and a series of writes to character types within that loop [2]. In total there are three “unnecessary” loads from memory that take place within the loop, due to the writes. The string size in the loop condition, as mentioned, but also the data pointers for to and from.
C++20 comes with the std::u8string type that is the string equivalent of char8_t and does not have the aliasing issue, so we can fix the problem by replacing std::string with std::u8string. Unfortunately, by the nature of the code in the body of the loop, on this occasion auto-vectorisation cannot take place. Instead, we end up with a loop that simply has to do three fewer reads from memory. A Compiler Explorer session with the original and the updated version can be found here. The primary differences are shown in the following code snippets.
In the first snippet we have the head of the unoptimised version. Line 45 is the head of the loop. On line 48 the destination pointer is loaded, on line 51 the string size is loaded, and on line 54 the source pointer is loaded. This occurs on each iteration of the loop.
In the second snippet we see the same code, but for the optimised version. The only memory accesses are the necessary ones, i.e. the write to memory on line 158 and the read from memory on line 163.
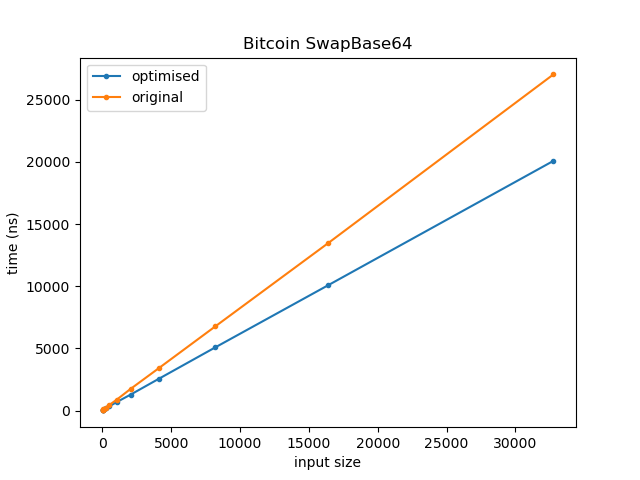
Running both versions over strings from size 8 to 16M (increasing in powers of 8) we get the following:
For clarity, the graph of the lower 32k looks as follows:
The optimised version executes approximately 63% of the instructions as the unoptimised version, and is on average 1.28x faster.
Monero
The next example comes from the Monero project. By this stage, I had come to the conclusion that the query focused on loop conditions had, by far, the best reward to effort ratio. The others tended to have a much worse false positive/true positive ratio, and require a lot more reasoning in order to distinguish true positives from false positives. The examples that they found also tended to be harder to mitigate in order to fix the issues.
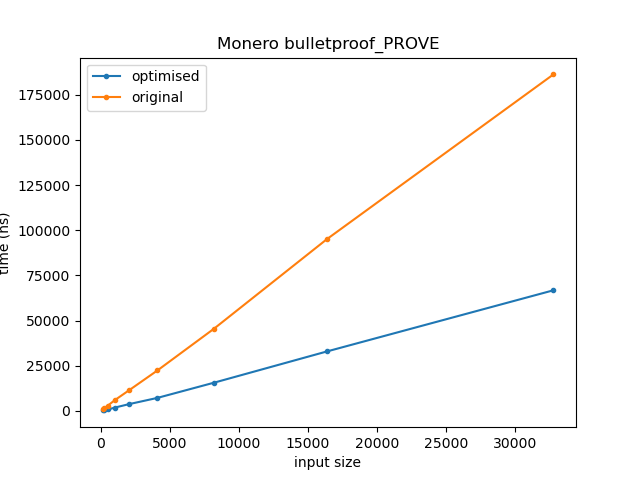
bulletproofs.cc rct::bulletproof_PROVE
rct::bulletproof_PROVE is found in src/ringct/bulletproofs.cc. It contains a loop that follows a similar pattern to what we have seen so far.
At a glance, this loops like a simple copy loop, for which the compiler should be able to generate assembly which performs all 8 assignments to sv[i].bytes at once. However, as the bytes array has a char type, after each assignment the compiler must generate code to reload several previously loaded values. The resulting assembly looks as follows, with most of the memory reads being unnecessary:
Resolving the issue is straightforward. As before we can simply change the type of the bytes array to be char8_t. With this change the compiler generates the following for the loop body:
As desired, we are now performing all 8 assignments in one go. The performance improvements are as you’d expect. The following graphs time on the y-axis against inputs with sizes in the range 2^6 to 2^14.
I’m unsure how big the keys used for this function are in reality, but the speedup is around 3-4x for sizes in the range 128 to 8192.
I think by now the sorts of patterns this approach tends to pick up should be clear, so let’s move on to answer the original questions I set out at the start of this section.
Analysis
The high level questions I had in mind at the start were as follows:
Q1. Do the queries actually work at all? Meaning, can we get a result set in a reasonable amount of time, with a reasonable false positive to true positive ratio.
Yes, the queries work, but there are some important details which I’ll get to in a minute.
Even on larger codebases the total query execution time is typically not more than a few seconds. I haven’t gathered precise numbers on the true positive to false positive ratio due to time constraints, but empirically I would say it is ‘reasonable’. To find the sort of patterns we are looking for it is sufficient to do syntactic pattern matching within functions, so we avoid the need to perform the types of semantic analysis that tend to lead to false positives. Many of the false positives are due to flaws in my queries that could probably be fairly trivially fixed by someone better at CodeQL than me.
There are a few important notes to be added here.
Detail #1: The Loop Condition (LC) query is much less prone to false positives than the other queries that are more generic, and has a much better effort-to-reward ratio. It is worth discussing why this is, as the reasons are helpful in understanding the limitations of using CodeQL to hunt for performance issues in general. By “effort-to-reward ratio”, I mean the effort one must undertake to both triage a finding into true positive versus false positive, plus the effort required to fix the found aliasing issue, versus the reward in terms of the speed-up of the code as a result of fixing this issue.
The LC query looks for loops that read from memory in their loop condition and also have a write through an aliasing type in their loop body. Alongside these properties, there are a couple of others that, for the sake of brevity I did not go into when presenting this query earlier. They are that it requires that the loop body is linear (no branching), and if there are any function calls then the called function is inline (and recursively any such inline function is also linear, and only calls other inline functions). The reason for focusing on loops without branching is that a true positive means a vectorised alternative is more likely attainable, and the reason for avoiding loops with non-inlined function calls is that quite often in such situations the compiler will generate code to reload values from memory after the function call, even if we remove the aliasing write from the loop. The query containing these extra restrictions can be found here.
So why does the LC query result in fewer false positives, and have true positives that have better performance improvements? The latter is straightforward: since we’re looking at loops, by their nature they execute repeatedly and thus any improvement we find is magnified in comparison to straight-line code. Since we’ve restricted the loop body in various ways there’s also a chance that when we find a loop that matches our pattern it may be vectorisable, or at least that the improvements that we make will be significant in comparison to whatever else is in the loop. Due to the fact that these loop bodies tend to be small, the effort required to determine what changes are necessary to fix the aliasing issue is also usually low.
As for why the LC query has fewer false positives, again this comes down to the restrictions that we place on the loop body for matching results. We are pattern matching at the source code level, but fundamentally the properties that we care about are patterns over assembly code. Why is this important? Well, our queries describe patterns in source code that we think should result in assembly code that results in “unnecessary” reloads of data from memory. However, the compiler’s optimisation passes are complex and there are a bunch of different things that may result in a value being cached in a register or spilled to memory. Some of these aspects can be captured as syntactic patterns, while others cannot (e.g. register spilling decisions or even minor compiler bugs), and some are situationally dependent, or even compiler dependent. We can therefore have “true positives” that are true in the sense that at the source code level the code does match the pattern we are after, but, despite this, even if we were to remove the aliasing write we would still not get more optimised code that does not contain the “unnecessary” load due to aspects of the surrounding code and the decisions the compiler makes as a result.
The impossibility of capturing the compiler’s internal reasoning in terms of CodeQL queries means that the more code that is spanned by a finding, from the first load of a value to its later reuse, the more likely it is that in between those points will be something other than the aliasing write that would cause the compiler to have to reload the value anyway, even if we remove the write. The other queries, besides LC, have fewer restrictions and thus tend to span code blocks that are larger and more expressive, and thus have more of these sorts of “false positive” findings where removing the aliasing write does not lead to any benefit. We could of course add the restrictions from the LC query to the other queries, to require linear code and no function calls. This would probably help with the false positives. However, I haven’t bothered to do this as I don’t think these other query types are likely to have a reasonable effort-to-reward ratio, even with this change. As mentioned, the effort to reward ratio is much higher with loops so I think that’s likely where the sweet spot is for this type of analysis. If I wanted to pursue this further, I would put my time into expanding the types of syntactic patterns that match loads from memory in the loop condition, rather than trying to make the more generic queries more usable.
Detail #2: As the setup for my test was “get some C/C++ codebases and run the queries”, I have no ground truth. Therefore we have no real clue what the false negative rate is. Above, I have argued for the usefulness of the LC query, partially due to the positive effect of the restrictions it imposes on the ratio of true positives to false positives. It’s unlikely this is a free lunch, and my guess is there are loops that have the aliasing issue that we are looking for, but that are excluded by the LC query. I haven’t come across any, but I also haven’t looked. If you happen to find one, let me know.
Detail #3: I also ran the queries on a few C codebases, namely the Python and PHP interpreters, and the Linux kernel. In these codebases there were some true positives, but none which would have any meaningful impact on the function’s performance were they fixed.
Q2: For the true positives, can we optimise the code so that the aliasing write is either removed or the code is restructured so that its impact is limited. If so, what sort of performance improvement do we get as a result?
In short, yes, we can, and the performance gain depends on the nature of what the code is doing. This is mostly answered above, but to restate the most relevant part: it pays to put one’s efforts into triaging results that are likely to have a significant pay off if they are true positives. Loops, in other words. Alternatively, if one has functions that are called a lot, that would fit the bill for the same reason.
For the more generic queries that did not focus on loops, I found trying to both triage and optimise them to be a painful process for the reasons mentioned in Caveat #1 of Q1. There was often a significant amount of code in between the first load from memory and the second, and trying to reason about whether the compiler will have the need to reload at the second point, even if we remove the aliasing write, was error prone.
Q3: How, if at all, would this analysis fit into a development workflow or CI/CD pipeline?
We can split this into two parts: inline analysis as the developer is writing code, versus analysis of an entire codebase. In both cases, as with any kind of analysis, the question we are trying to answer is “Will this have meaningful impact, without negatively impacting development velocity or annoying the developers”. However, the actual work a developer may have to do to respond to an alert (in terms of reasoning, coding and validation of results) is drastically different between these two scenarios, and so we need two different modes of operation.
In the case of a developer writing a new piece of code, if their IDE alerts them to a loop matching the properties we’re looking for, it is likely to be an easy decision as to whether to adjust the code or not. They will have some idea as to whether the code is likely to be “hot”, and what the impact of that may be. As the code is new, there’s no prior version to benchmark against, no resistance is likely to be encountered in the PR review process (again, no previous code being changed), and if the fix is something like “use char8_t instead of char” then the developer is likely to do it as there is no cost to them. In security this is a similar scenario to your IDE alerting you to use of a potentially unsafe function. Even if you know the code will never be reachable via an attacker, you may use the proposed safe version anyway just to shut up the linter and to follow best practices.
The case of analysing an entire code-base is a bit more tricky. One of the problems with static analysis in security is that if your automated analysis is purely static, it is easy to end up drowning in low/no-impact reports in this scenario. This is why fuzzing is so appealing: assuming you are providing fuzz inputs through the same input interface that an attacker can access, you generally know that each issue found is both a true positive and worth solving.
For performance issues, we have a similar problem with static analysis: given a result set, we may find it difficult to know where to put our energy in terms of what to first triage, and then fix. We are not likely to have the time to fix everything, and even if we do, the process of validating those fixes and getting them through a PR review may be a significant effort. So, how do we get something akin to fuzzing’s clarity of signal?
Continuous profiling in production will give it to us quite easily. The results of the CodeQL queries can be ranked based on the CPU consumption observed by the profiler in the real world, and the developer’s efforts therefore focused on findings most likely to have meaningful impact.
Conclusion/Open Questions/Future Work
Practical static analysis for performance analysis is a wide open topic. However, regardless of what direction it takes, the best results will be achieved in conjunction with data from continuous profiling. As outlined in the previous post, there are at least three ways to do this combination: context-for-ranking in which continuous profiling is used to rank the output of a static analysis, context-for-operation in which the static analyser requires data from continuous profiling to operate at all, and ranking-for-analysis, in which we have a heavyweight, slow, static analysis that doesn’t scale to an entire codebase, and therefore continuous profiling is used to guide where to target it.
In this post we saw an example of an analysis that requires context-for-ranking from a profiler. Without it, false positives, and the non-negligible effort required to triage, fix and benchmark each finding, means developers will lose patience with the tool after burning their energy on irrelevant findings, even if they turn out to be fixable true positives. A profiler changes this dynamic, ensuring that the developer’s efforts are focused on findings that are most likely to have a meaningful impact on performance.
As for using CodeQL for this sort of pattern matching, the experiments I did for this post were enough to convince me it’s worth investigating further. I found some good results, that lead to meaningful performance improvements, yet at the same time there were some notable misses (the Linux kernel, PHP and Python), and the false positive rate combined with the effort to triage, fix and then benchmark changes, mean I still consider the approach to be “experimental” rather than developer ready. There are two big open questions for me:
What sort of properties can we query for statically? The type aliasing issue is a quirk of C/C++’s type system. Are there other language-level properties we could capture similarly? Are there API usage patterns that lead to performance issues that we can query for? An example that comes to mind is the use of std::vector inside loops that would otherwise be vectorisable. My guess is there are a few such things, but the question is: how often do they occur, and how meaningful are they? Beyond these, in security, we have seen an evolution from looking for language and API specific issues, to looking for patterns that are specific to a particular code-base but tend to be frequently reintroduced and high impact. Would this be worth pursuing in performance as well? i.e. Are there performance bug types that may only be specific to, for example, Firefox, but that repeatedly occur there due to a particular internal API or pattern?
Would it make more sense to do this analysis at the assembly level? Doing so would side-step the problem of having to try and encode how we think source code will be transformed into assembly, and it is the assembly that matters in the end. However, it can be more difficult to implement common static analysis algorithms on assembly, and scaling the analysis may prove more difficult. In reality, I expect both source level and assembly level analysers will be necessary. For many properties, the false positives introduced by working at the source level will either be irrelevant or manageable, and for those properties the convenience of working at a source level is attractive. Some other performance issues (e.g. assembling layout or alignment) can only be discovered by looking at the running binary though, and so a platform for writing and running analysis at this level will be necessary (e.g. Binary Ninja, IDA, Ghidra).
And that’s a wrap. If you made it this far I hope you found it interesting! If you’ve any questions, leave a comment below or you can find me on twitter @seanhn or LinkedIn.
This is the first post in a two part series on combining static and dynamic analyses for performance optimisation. I’ve split them up as otherwise it’ll be horrifically long, and the second post will be online later this week. This post lays out some high level context, discusses why we should combine analyses, and has a loose framework for thinking about analysis combination. I’ll then explain a straightforward combination of continuous profiling with pattern matching on library names and versions which has led to 60%+ performance gains per service in real customer infrastructure.
In the follow-up post, I’ll discuss experimental work I did last year on using CodeQL to search for performance optimisation opportunities in C/C++ codebases. CodeQL is typically used to find security vulnerabilities, but I’ll show how it can also be used to find C++ code patterns that may lead to the compiler producing machine code that is 10x, or more, slower than it could be. Primarily, these patterns relate to code constructs that prevent the compiler from auto-vectorising loops and where, with some minor type changes or reordering of statements, we can achieve significant performance improvements.
Why Combine Static and Dynamic Analyses?
A few years ago I co-founded optimyze.cloud, and we built Prodfiler (now the Elastic Universal Profiler) – a fleet-wide, continuous, whole-system profiler. That is, a profiler that is sufficiently efficient that it can be always on, everywhere, profiling the entire system on every machine in your fleet. Enabling Prodfiler/EUP gives insight into exactly which lines of code are costing you CPU resources across your entire fleet, regardless of whether it is in userland, the kernel, native code, or some higher level runtime runtime. That’s fantastic, but, when presented with the top 10, or 100, most expensive functions in your fleet, the question arises: is it “fine” that these functions are that expensive, or not? And if not, why are they so expensive and what can be done to remedy matters?
If you’re lucky, the expensive functions are in code that you wrote and understand, and the answers to these questions may be easily arrived at. If you’re unlucky, it’s in some third party library you’re unfamiliar with, written in a language you don’t know, and on top of a runtime you’ve never heard of. A common question from our users is whether, instead of just a list of expensive functions, we could also suggest root causes or, even better, fixes. It is from here we come to the need for some sort of complementary analysis that can “reason” about why a particular chunk of code may be expensive, and if possible suggest a way to make it less so.
A lesson I’ve taken from building bug finding and exploit generation tools is that the sweet spot for tooling usually brings together:
Large scale, fast, dynamic analysis, involving the execution of software/system and observing what it does under a large and diverse set of inputs.
Automated static analysis, that may augment, or be augmented by the dynamic analysis.
A well designed UI/UX that enables exploratory workflows even in the presence of large amounts of data. The UI should bring together all available context, while supporting filtering, slicing and searching, with little to no perceptible lag.
With Prodfiler we have 1 and 3, but 2 is relatively unexplored in the performance world, and certainly in the context of combining it with continuous profiling.
My belief is that, just like security, the sweet spot for performance analysis is in the intersection of points 1-3, with dynamic and static analysis being mutually beneficial, and an intuitive and performant UI being game changing. In this post I am going to focus exclusively on the static analysis part of the equation. If you’d like to learn more about how to build a high performance continuous profiling engine then we have an initial blog post on this topic over on the Elastic blog, and will have more in the future.
Modes of Combining Dynamic and Static Analysis
In general, in program analysis R&D, there are no hard and fast rules on what does and does not work well, and it’s an area where’s there’s plenty of ongoing work in both academia and industry. It’s also not the case that one might stick to combining one static analysis with one dynamic analysis. You may even decide to skip one form of analysis entirely, and chain a bunch of exclusively dynamic analyses, or vice versa. As an example, for the purposes of bug finding, an over-approximate but fast abstract interpretation based analysis could be applied to every function in the code base to find potential bugs. The potentially buggy functions could then be passed to a symbolic execution engine to validate the bugs in the intraprocedural context. Finally, a fuzzer could be used to try and find paths to those buggy functions which exercise the conditions required to trigger the bug. For a concrete example, check out Sys, which combines static analysis and symbolic execution to leverage the strengths of each to find bugs in web browsers [code] [paper & talk].
When it comes to performance optimisation and analysis, there are three modes of operation that I can think of where multiple analyses may be mutually beneficial:
Context-for-ranking in which a dynamic analysis provides a ground truth on the most expensive parts of the system, ideally when it is executing in production on real workloads. This context can then be used to rank the results of a static analysis. Ranking is important for two reasons. First, developers have finite time. An approximate analysis with false positives will require a developer to validate each result. If we want a developer to actually use the tool then we need some way to ensure that their efforts are applied to the most impactful findings before they run out of time or energy. Second, whether a finding from a static analysis tool intended to find performance issues is even valid or not may hinge on whether the code in question is on a hot path. The results of the static analysis are essentially incomplete unless combined with the context indicating what code is hot on production workloads. An example of context-for-ranking might be continuous CPU profiling in production being used to rank the output of an analysis which lists the loops in a program that the compiler failed to auto-vectorise. If a loop is unvectorised in a function that only executes once on startup then it probably doesn’t matter, but continuous profiling gives you a way to filter out this sort of noise and focus on the loops that are significant.
Ranking-for-analysis in which a lightweight dynamic analysis provides information on the most expensive parts of the system so that a heavyweight analysis can be focused there (or alternatively, so that more of a lightweight analysis can be done on those areas). Some analyses are CPU/RAM intensive to run. An example of this would be symbolic execution. Were we to use such an analysis, or something similarly heavy, in the context of performance optimisation then we would want to use some other data source to indicate which functions are most expensive, and focus our efforts there.
Context-for-operation in which one analysis provides data that is necessary for another analysis to operate at all. Examples here would be things like profile guided optimisation/AutoFDO or a post-link time optimizer like Facebook’s BOLT. For these, profiling information for them to operate at all. I’ll give another example of an analysis of this kind in the next section that is incredibly straightforward, yet effective.
Low Hanging, Delicious, Fruit
The second post in this series, discussing using CodeQL to find optimisation opportunities, is in the category of “intellectually interesting research warranting further investigation”, but is still quite early stage. In the interests of giving some practical advice to go along with the ivory tower thinking, here’s a simple, obvious, and very effective analysis combination that has repeatedly given our customers wins across all sorts of systems.
The most low hanging fruit in combining static and dynamic analysis for performance optimisation is to just pattern match on the libraries and functions that are most significant in the performance profile of an application, and for which we know there is a functionally equivalent, optimised, version available. We have real world data with customers having huge performance wins following this approach. In Prodfiler this can be done by looking at the TopN view, which ranks the top N most expensive functions across your entire infrastructure.
Some concrete examples we’ve come across:
If significant time is spent in functions related to memory allocation (e.g. malloc, free, realloc etc), and the application is using the standard system allocator, then it is likely that it will get a performance improvement by switching to a more optimized allocator, such as mimalloc or jemalloc. An example of this is described in this blog post, in which I found an application spending 10% of its time dealing with memory allocation. Replacing the system allocator with mimalloc cut this time in half, and increased overall performance of the application by ~10%. An internal team at Elastic encountered a similar pattern and, alongside the reduced CPU overhead for their application, reported a 20% drop in RAM usage by swapping out their allocator for jemalloc.
If significant time is spent in zlib then switching to zlib-ng can bring improvements. A customer of ours had a 30% improvement in application performance using this change.
If a significant amount of time is spent processing JSON, or in serialisation and deserialization, then there is a huge amount of variance in the performance of 3rd party libraries that do this. Often the version provided by the runtime, or that is most popular, can perform dramatically worse than the state of the art. A customer of ours had a 60% reduction in one of their heaviest workloads by replacing the JSON encoder they were using with orjson.
This process is straightforward, and has an excellent effort-to-reward ratio – look at the results, google for “optimised library X”, ensure it meets your functional and non-functional requirements, replace, redeploy, measure, move on. If you’re starting out with combining analyses, then start there. This can be easily automated and integrated with your notification framework of choice. There are actually a couple of approaches to implementing this “grep for libraries” solution. One is to write a script that compares function and/or library names in your profiler’s Top N output against a list of known replaceable libraries. This would be an example of a context-for-operation combination of analyses, with profiling providing the context for the regex/grep script to run. Alternatively, you could have a tool which scans all of your base container images for libraries for which you know an faster alternative exists. Sending this information as alerts to developers is just going to annoy them though, as who knows if those libraries are even loaded, let alone have code on a hot path. However, combined with a continuous profiler you can filter out such noise, rank the results by their impact across your entire fleet and then dispatch alerts only in cases where replacing the library could have significant gains (an example of context-for-ranking).
Conclusion
I hope the above was useful in laying out a framework for thinking about ways to combine analyses. If you’re a SRE/SWE and integrate the continuous profiling/grep-to-win approach in your environment, I’d love to hear how it pans out. There’s lots of scope for R&D in this space, so if you’ve got any interesting and useful examples of analyses then drop me a DM on Twitter. I’ll follow up later this week with the second part in this series, which will discuss using CodeQL to find loop vectorisation opportunities.
How do you almost 2x your application’s performance with zero code changes? Read on to find out!
This is a repost of a blog I originally wrote on prodfiler.com on October 4th 2021. Prodfiler was acquired by Elastic is is now the Elastic Universal Profiler.
In this post I will walk through how we can use Prodfiler to unearth areas for optimisation in K2 (paper, video), an optimising compiler for eBPF. K2 is entirely CPU bound and uses a guided search technique that relies on the ability to create and check candidate solutions at high speed. With Prodfiler we can easily discover which components of K2 consume the most CPU cycles, allowing us to optimise them accordingly. The end result is a version of K2 that is 1.4x-1.9x faster, meaning it can explore a significantly larger search space given the same resources.
To foreshadow where we are going, the improvements discovered come from:
Replacing the system allocator with better performing alternative, namely mimalloc.
Assisting the compiler in auto-vectorising a series of hot loops.
Applying PGO and LTO to K2 itself and to Z3, its most significant dependency.
Introduction
As more use-cases are discovered for eBPF, with many of them on critical paths, the performance of the eBPF code generated by compilers is increasingly important. While clang usually does a good job of producing efficient programs, it sometimes generates code that suffers from redundancies, unusual choice of instruction sequences, unnecessarily narrow operand widths, and other quirks that mean a hand-optimised program can be significantly faster. Hand-optimisation of eBPF instructions is challenging, time consuming and error prone and so, as with compilation for more traditional target platforms, there is a market for tools that spend time upfront in compilation in order to gain performance at runtime.
In August of this year, researchers at Rutgers released K2, an optimising compiler for eBPF code. K2 takes as input an existing eBPF program and searches for a faster and smaller program that is semantically equivalent to the original. In their paper they demonstrate that their approach can be used to reduce program size by 6-26%, lower the average packet-processing latency of those programs by 1-55%, and increase throughput by up to 5%, relative to the best clang-compiled programs.
To drive its search K2 uses MCMC with the Metropolis-Hastings acceptance criteria [1]. A good introduction to MCMC/MH can be found here, but for our purposes it’s sufficient to just think of MCMC as a search technique that, in its inner loop, must generate a new candidate from the current state and assign a cost to it. The next current state is then decided upon randomly using the costs of the current state and the candidate state to bias selection. Given a fixed time budget (and assuming sane candidate generation and a reasonable cost function) the quality of the result is directly linked to the number of states that can be explored in that time period. MCMC-based applications are thus prime targets for tools like Prodfiler, as any performance gains that we can eke out are likely to enable the application to find higher quality results using the same resources.
A Brief Overview of K2’s Architecture
For some context on what exactly we will be optimising, lets quickly run through the components of K2. The above diagram is from the K2 paper, which is very readable and highly recommended if you’d like more detail.
As mentioned above, being MCMC-driven, the core of K2 is:
Generate a new candidate from the current state.
Assign that candidate a cost.
Set the current state to new candidate state, conditionally on the candidate’s cost and the current state’s cost.
Algorithmically, almost all of the heavy lifting goes on in step 2. To calculate the cost of a candidate, K2 interprets it using a custom userspace eBPF interpreter on a set of inputs. For these inputs, if the candidate produces the same outputs as the original program, K2 then converts the candidate to a symbolic representation and uses the Z3 theorem prover to perform an equivalence check. The inner loop of the MCMC search is therefore computationally quite intensive, with each candidate requiring a significant amount of work to evaluate.
Setting Up
Setting up Benchmarks
K2 itself can be found on GitHub, and conveniently the authors have also uploaded a conference artifact containing tests and benchmarks that were used to generate the results in their paper. I have cloned this repository here in order to add some helper scripts for use in this post. The primary K2 repository is a bit scant on information on how to actually install and run it, but fortunately there is an installation script here, which one can follow as required. An example of how to run K2 to optimise an eBPF program can be found in this script. That script will invoke K2 on 11 different eBPF programs to try and find more efficient implementations. We will use it as the basis for our benchmarks as the input eBPF programs are diverse, and we can be relatively certain that if we find optimisations that make K2 run faster across these input targets, then they should generalise.
One final point on setting up the benchmarks is that I have cloned K2 here in order to provide a default Makefile that will build a reasonable binary for us to compare our improvements against. The standard Makefile that comes with K2 appears to have an error, and does not specify an optimisation level when compiling most files that make up the program, and thus by default you get no optimisation and quite poor performance. My Makefile specifies -O3 -march=native as a default.
Benchmarking and Optimising with Prodfiler
Getting started with Prodfiler is straightforward. Follow the docs here to create a new project and deploy Prodfiler in a few clicks. Once it is up and running we can then gather our baseline data by running the benchmarks mentioned above. The script I have created to do so can be found here. By default it runs each of the 11 benchmarks 15 times. We’ll use that to gather our results and ensure our optimisations generalise, but there’s also a ‘fast’ mode that runs 3 of the benchmarks 3 times each, which can be useful for quickly checking a hypothesis.
Act I – Where the M and C in MCMC stands for MalloCMalloC
Opening the Top N Functions view of Prodfiler gives us the following (hint: Exclusive CPU means the CPU usage of the function alone, excluding the CPU usage of the functions it calls. Inclusive CPU means the CPU usage of the function itself and the CPU usage of the functions it calls).
The Top N Functions view is my usual starting point to get a feeling for where an application is spending its time. Fairly often one or more entries in the Top 10 Functions will make me think “Huh, that’s weird”, and provide a clue as to potential performance wins. This view is particularly good at surfacing functions where each individual execution is cheap, but the function is called so often that it comes to unexpectedly dominate execution time.
Two things in particular stand out in the Top 10 Functions of K2. The first is that a significant amount of time is spent assigning and retrieving items from an STL container. Based on the function names and the source file in question we can deduce that the container is a std::vector<bool>, a notoriously weird container. A std::vector<bool> can be the right choice in situations where memory usage is a concern, but if one is primarily concerned with CPU usage then there are better options. OK, that’s a good start, but lets park it for the moment and continue down the list and see if there are even easier gains to be found.
The second item that stands out is that in positions 5 and 6 we can see the malloc and free functions. In fact, upon expanding the above list to encompass the top 20 functions, I discovered that malloc-related functions take up 5 out of the top 20 spots. If we sum their CPU usage we learn that a full 10% of the application’s CPU time is spent on memory management! Applications that spend so much time in memory management can almost always be sped up in two ways. One approach is to analyse the application’s usage of memory, and try to tune that to simply make fewer calls to the memory management functions. The second approach is to swap out the system allocator with something else. The latter approach is usually far less work [2], and is what we will go with here. There are many choices of allocator these days, with jemalloc and tcmalloc being particularly well known. A more recent entry into the field is mimalloc. In benchmarks, mimalloc compares favourably with the other available options, and is our choice for this post.
mimalloc is a drop-in replacement for the system allocator. Using it is as simple as adding its installation location to LD_PRELOAD and running your application.
With this change we can see that the free function has dropped out of the Top 10 Functions entirely, and if we sum the usage of all functions in mimalloc we find that memory management has dropped to approximately 5%, instead of the 10% it was at previously. Excellent! That’s 5% of the CPU budget that will now hopefully be allocated to more useful things.
So, what sort of performance gain do we get from this? The following chart shows the mimalloc runtime versus the default runtime. The X-axis shows the speed-up of the mimalloc run as a factor of the default run. Note: The Y-axis is truncated starting at 0.8, to make it easier to see size of the changes.
Across the benchmarks we see an average speed-up of 1.08x, with a min of 1.05x and a max of 1.12x. Not bad for a zero effort change, but lets see what else we can find!
Act II – In which std::vector<bool> murders performance
With the easiest of wins out of the way, we may now have to do some actual work. Fortunately, we have a clear starting point. Returning to the Top N Functions we can see that the top two items alone account for 15% of the CPU budget, and are related to access to std::vector<bool> containers, as mentioned previously. That is a fairly extreme proportion of CPU budget to be allocated to any one built-in data-structure, and my expectation in such scenarios is that there are gains to be had. First, we need to figure out what std::vector<bool> is being used to represent, and how it is being used. To answer this question, Prodfiler provides a call-graph for each function which can be accessed by clicking on the function name in the Top N Functions view (or by ctrl-clicking on a function in the Flamegraph view). The call-graph for std::vector<bool>::operator= looks as follows:
We can see that two functions (prog_state::init_safety_chk and inout_t::operator=) are responsible for practically all of the calls to this function. These same two functions are also responsible for all of the calls to std::vector<bool>::operator[], the second function in the Top N Functions list. Armed with this we can jump into the code to try and figure out why so much time is being spent operating on these vectors, and what we can do about it.
The init_safety_chk function is as follows (source):
So we have a series of bools being copied about on each safety check of a candidate. The two containers representing whether a register is readable and whether memory is readable are of fixed size, 11 and 512 respectively. Looking at the code for inout_t::operator= we see a similar pattern. The copies in inout_t::operator= will have more of an impact than those in init_safety_chk as this assignment operator is called in the calculation of the error cost for a candidate the same number of times as there are concrete inputs available on which to interpret that candidate.
Given that these vectors are of fixed size, and in principle at least should contain very little data one might wonder why we are spending so much CPU on copying them, even if the copies do happen multiple times per candidate. On a CPU with SIMD instructions, shouldn’t copying around this amount of data just be a matter of a loop-free block of instructions each time? Well, lets see what the compiler does with that code. Note: The disassembly screenshots in this post are not from Prodfiler, but from Binary Ninja.
The above code is generated to copy the contents of the stack_readable vector. As we can see, we certainly don’t have a straight-line sequence of SIMD instructions, but instead a loop with a branch in the middle that will iterate STACK_SIZE times. The reason for this becomes obvious if we have a look at the implementation of operator= in stl_bitvector.h:
OK, so clearly the compiler isn’t going to be able to help us out here and nicely vectorise that automatically. So what are our options? Well, K2 does not have a very high memory footprint, and the memory savings from using std::vector<bool> instead of, for example, representing the same information as a vector of bytes, are not significant in the grand scheme of things. My first thought was to simply replace the bool type with a uint8_t. However, upon doing so and rerunning the benchmarks the performance improvement was paltry, and nothing like what I would have expected if a byte-by-byte copy such as the one above was replaced with straight-line SIMD. Back to the disassembly we go, and discover that the copy loop has become the following:
For some reason, instead of straight-line SIMD the compiler has decided to produce a byte-by-byte copy loop in which on each iteration the source and destination pointer are loaded from memory. I asked about this on Twitter and Travis Downs responded and pointed out that the issue is that in C++ the uint8_t type can alias all other types! Therefore the compiler cannot guarantee that each write to the vector does not modify the source and destination pointers, and thus must reload them from memory on each loop iteration. Travis has an excellent blog post that further expands on this here.
Travis had a number of suggestions for ways to hack around this issue, and the one I decided to go with was to use C++20’s char8_t type instead of uint8_t. This type does not have the aliasing problem, and gives us our desired straight-line SIMD code:
As you can see on the left-hand side, there is also code generated to do a byte-by-byte copy, but this will never be reached in practice as it is only entered if the source and destination vectors overlap. So, how does this help our performance?
Rather well, it turns out! By replacing the vector<bool> with vector<char8_t> and enabling the compiler to auto-vectorise the relevant loops we have an average speed-up of 1.31x over the mimalloc version, with a maximum of 1.57x and a minimum of 1.12x. Over the default version, we now have an average speed-up of 1.43x, with a maximum of 1.75x and a minimum of 1.22x. Looking at the Top N Functions view we can also see that operator= and operator[] are now 0.82% 0.62% of the total respectively, down from 12.3% and 3.93% [3].
What this means in practice is that with a 1.22x-1.75x speed-up, given the same CPU budget K2 can perform a significantly larger search. Concretely, in the benchmark with the most significant improvement (xdp_map_access) by default K2 can explore approximately 4600 candidates per second, but with our improvements that has jumped to approximately 8000 candidates per second!
Act III – Z3
An average speed-up of 1.43x is nice, but before wrapping up lets have one last look at the profiling data, to see if anything else stands out.
A glance at the Top N Functions shows us that memory management functions remain significant, with around 7.5% CPU across malloc and free (positions 1 and 10). There are a few directions we could take with this, including reviewing K2’s memory allocation patterns to see if they are sub-optimal in some way, or potentially applying PGO/LTO to mimalloc in the hope of making it faster. The former option is likely to be a bit of work, and the latter option I felt would be unlikely to give more than a couple of percentage points in improvement. The function in position 7 is also interesting in that from the callgraph we can see that read_encoded_value_with_base is used as part of C++ exception handling. Looking into the code shows that K2 uses exceptions as mechanism to communicate non-fatal errors from deep in the call-stack to higher up functions. We could rewrite this to use return values or output parameters to indicate the same information and save on this overhead, but again this is likely to be a decent amount of work for not a lot of gain. The final observation I have from this data is that 4 of the Top 10 functions are in Z3, and it is this one that we will dig into as it gives a hint that any optimisations to Z3 are likely to have a significant impact.
Prodfiler provides two ways to dig into how these functions are used. The first is the callgraph as we saw earlier, and the second is the flamegraph, which we will use now. The flamegraph is quite useful when one wants insight into the most costly call-stacks, in a more information dense and easily navigatable fashion than a callgraph (at the expense of not representing the sum totals of CPU usage associated with each function, but instead representing data per call-stack).
The flamegraph confirms our hypothesis that Z3 is a worthy target for optimisation. We can see in the graph that the Z3_solver_check() function and its children are responsible for a full ~46% of the work done by K2! There are two ways we could attack this:
It is possible that K2 is calling Z3 more than it needs to. If you recall from earlier, Z3 is only called if K2 fails to distinguish a candidate program from the original program via interpretation of that program on a set of inputs. It is possible that by generating a more diverse set of inputs we could distinguish candidates from the original without going to Z3 as often.
We could attempt to make Z3 itself perform better.
Given enough time we would most likely do both (1) and (2), and possibly even start with (1). However, by this stage I was starting to enjoy the challenge of trying to improve K2’s performance by making the least intrusive changes possible and so decided to go with (2) alone. Now, improving Z3, one of the most powerful and popular theorem provers in the world, would actually be a lot more work than option (1) if we actually wanted to do so by making algorithmic or implementation changes. We have another option available to us though: modifying the manner in which Z3 is compiled.
Both gcc and clang support Profile Guided Optimization (PGO) and Link Time Optimization (LTO) [4]. PGO and LTO are complementary and using both one can often get performance improvements in the range of 5-20%, with high single digit improvements being a reasonable expectation. For various reasons very little open-source software is distributed compiled with PGO/LTO, or even comes with a build target that will enable them (although this is changing). Fortunately, it’s usually straightforward to do it yourself [5].
PGO is a three-step compilation process in which one first builds an instrumented [6] version of the application, then runs that application on a series of inputs in order to gather data, and then finally recompiles an optimized version of the application using that data. For the first phase I randomly selected three benchmarks (socket-0, xdp_kern_xdp1 and xdp_cpumap_enqueue) and ran each three times. These three benchmarks are included in the below graphs, but it is worth keeping in mind that there is a potential for over-fitting [7] to their characteristics which may mean one would want to discount the results on those and focus on the others. In the computation of the various min/max/mean values below I have excluded them.
Applying PGO and LTO to Z3 has gained us on average 1.1x performance impovement over our previous version, with a max of 1.17x and a min of 1x (identical performance as before). Overall, that brings us to an average improvement of 1.54x over the original version, with a min of 1.37x and a max of 1.79x!
As a final effort I decided to also then PGO (but not LTO [8]) K2 itself to give our final results:
PGO’ing K2 itself was good for another 1.03x performance gain on average, with a max of 1.09x and a min of 1x. These are modest improvements, but it is worth keeping in mind that on average 44% of the execution time of K2 is actually spent inside Z3, and so there is only so much that PGO’ing the rest of the code can do.
So, in the end, after swapping in mimalloc, replacing std::vector<bool> with std::vector<char8_t> and applying PGO/LTO, we have an average performance improvement of 1.62x, a maximum of 1.91x and a minimum of 1.42x. In practice what this means is that if we were exploring 10,000 states per second originally, on average we are now exploring ~16,000 in the same time budget, and in the best case we exploring almost twice as many!
Conclusion
In this post we have walked through how Prodfiler can be used as part of an iterative process to significantly increase application performance. The sequencing in this post is how I actually use Prodfiler – (1) set up benchmarks (ideally real workloads; Prodfiler’s overhead is low enough that this is feasible), (2) run them, (3) and then iteratively work through the top functions, flamegraph and callgraph, seeking out changes to the application itself, the environment, third party dependencies, or configuration, that can increase performance.
I view Prodfiler as a “Huh?”-generator, in that its various views tend to induce a “Huh – that’s weird” thought in my brain that is the first step along a path to figuring out why exactly some unexpected component is assigned as much CPU as it is. Sometimes the end point of that path is just resolving a misunderstanding of mine about the target software, but often it is discovering some overlooked characteristic that’s eating CPU in an unanticipated way. That is the true value of Prodfiler – it allows precise data to be gathered with zero friction, from individual applications to entire clusters, and visualises that data so that an engineer can easily scan it for “Huh?” moments. So, in conclusion, whether it is Prodfiler or not, I would recommend finding yourself a “Huh?”-generator. In combination with some persistence there are huge performance improvments to be found in the modern software stack. Happy hunting!
Footnotes
[1] This provides a good introduction to MCMC/MH, and the STOKE paper is worth reading for another example of stochastic search in program optimisation.
[2] Unless the ‘something else’ you are swapping in is a custom allocator, specifically designed for your application’s memory allocation patterns. That is of course a reasonable approach in some scenarios, but probably overkill unless you have really exhausted all other alternatives.
[3] After replacing vector<bool> with vector<char8_t> in the inout_t and prog_state classes and rerunning the benchmarks I saw that map_t::clear was now the second most expensive function, with 3-4% of the CPU budget. Upon looking into it I found another instance of vector<bool> that was causing the compiler to produce a byte-by-byte loop to zero out the vector. I also replaced this with vector<char8_t>, allowing the compiler to use memset instead of the loop. The results shown include the effects of this change as well.
[4] A useful high level overview of both PGO and LTO can be found here. See the documentation of gcc and clang for further information.
[5] In a future blog post I’ll go into PGO/LTO of Z3 specifically, but the gcc documentation on the flags -fprofile-generate, -fprofile-use and -flto are a good starting point. This StackOverflow post also has some high level information on PGO.
[6] There is another approach to PGO that uses a sampling profiler instead of instrumentation. The Google AutoFDO paper is a good starting point for information.
[7] I am unsure how significant this possibility of over-fitting actually is. K2 randomly generates candidates given a starting state, so even starting from the same state it is likely that the search space explored will not be identical, and thus the use of Z3 will not be identical.
[8] LTO’ing K2 resulted in the functions that operate on the vector<char8_t> types that we introduced being inlined in a variety of locations and for some reason once that happened gcc would no longer unroll and vectorise those loops. I’ll dig into this in a future post.
Over the summer I defended my PhD thesis. You can find it here.
To give a super quick summary (prior to a rather verbose one ;)):
Pre-2016 exploit generation was primarily focused on single-shot, completely automated exploits for stack-based buffer overflows in things like network daemons and file parsers. In my opinion, the architecture of such systems unlikely to enable exploit generation systems for more complex bug classes, different target software, and in the presence of mitigations.
Inspired by the success of fuzzing at bug finding, I wanted to bring greybox input generation to bear on exploit generation. As a monolithic problem exploit generation is too complex a task for this to be feasible, so I set about breaking exploit generation down into phases and implementing greybox solutions for each stage. I designed these phases to be composable, and used a template language to enable for communication of solutions between phases.
Composable solver solutions and a human-writable template language gives two, new, powerful capabilities for an exploit generation engine: 1) “Human in the loop” means we can automate the things that are currently automatable, while allowing a human to solve the things we don’t have good solvers for, and 2) If solutions are composable, and if a mock solution can be produced for any stage, then we can solve stages out of order. This leads to efficiency gains if a solution to one stage is expensive to produce, but we can mock it out and see if such a solution would even be useful to later stages, and then come back and solve for it if it does turn out to be useful. In practice I leveraged this to assume particular heap layouts, check if an exploit can be created from that point, and only come back and try to achieve that heap layout if it turns out to be exploitable.
My belief is that the future of exploit generation systems will be architectures in which fuzzing-esque input generation mechanisms are applied to granular tasks within exploit generation, and the solutions to these problems are composed via template languages that allow for human provided solutions as necessary. Symbolic execution will play a limited, but important role, when precise reasoning is required, and other over-approximate static analysis will likely be used to narrow the search problems that both the input generation and symex engines have to consider.
You’ll find a detailed description of the assumptions I’ve made in Chapter 1, as well as an outline of some of the most interesting future work, in my opinion, in the final chapter.
Background
I originally worked on exploit generation in 2009 (MSc thesis here), and the approach I developed was to use concolic execution to build SMT formulas representing path semantics for inputs that cause the program to crash, then conjoin these formulas with a logical condition expressing what a successful exploit would look like, and ask an SMT solver to figure out what inputs are required to produce the desired output. This works in some scenarios where there are limited protection mechanisms (IoT junk, for example), but has a number of limitations that prevent it from being a reasonable path to real-world automatic exploit generation (AEG) solutions. There’s the ever present issue with concolic execution that scaling it up to something like a web browser is a bit of an open problem, but the killer flaw is more conceptual, and it is worth explaining as it is the same flaw found at the heart of every exploit generation system I am aware of, right up to and including everything that participated in the DARPA Cyber Grand Challenge.
This earlier work (mine and others) essentially treats exploit generation as a two phase process. Firstly, they find a path to a location considered to be exploitable using a normal fuzzer or symbolic execution tool. ‘Exploitable’ almost always translates to ‘return address on the stack overwritten’ in this case, and this input is then passed to a second stage to convert it to an exploit. That second stage consists of rewriting the bytes in the original input that corrupt a function pointer or return address, and potentially also rewriting some other bytes to provide a payload that will execute a shell, or something similar. This rewriting is usually done by querying an SMT solver.
The conceptual flaw in this approach is the idea that a crashing input as discovered by a fuzzer will, in one step, be transformable into a functioning exploit. In reality, a crashing input from a fuzzer is usually just the starting point of a journey to produce an exploit, and more often than not the initial input leading to that crash is largely discarded once the bug has been manually triaged. The exploit developer will then begin to use it as part of a larger exploit that may involve multiple stages, and leverage the bug as one component piece.
Open Problems Circa 2016
From 2009 to 2016 I worked on other things, but in 2016 I decided to return to academia to do a PhD and picked up the topic again. Reviewing the systems that had participated in the DARPA CGC [3], as well as prior work, there were a few apparent interesting open problems and opportunities:
All systems I found were focused on entirely automated exploit generation, with no capacity for tandem exploit generation with a human in the loop.
No research I could find had yet to pick up on the notion of an ‘exploitation primitive’, which is fundamental in the manual construction of exploits, and will presumably be fundamental in any automated, or semi-automated approach.
All systems treated AEG as essentially a two step process of 1) Find a path that triggers a bug, 2) Transform that path into an exploit in one shot, rather than a multi-stage ‘programming’ problem [4]. IMO, this is the primary limitation of these systems, as mentioned above, and the reason they are not extendable to more realistic scenarios.
Nobody was really leveraging greybox input generation approaches (fuzzing) extensively, outside of the task of bug finding.
Almost all systems were still focused on stack-based overflows.
Nobody was working on integrating information leaks, or dealing with ASLR, in their exploit generation systems.
Nobody was working on language interpreters/browsers.
Nobody was working on kernels.
It’s likely that points 5-8 are the ‘reason’ for points 1-4. Once you decide to start tackling any of 5-8, by necessity, you must start thinking about multi-stage exploit generation, having human assistance, addressing bug classes other than stack-based overflows, and using greybox approaches in order to avoid the scalability traps in symbolic execution.
Research
With the above in mind (I didn’t touch 6 or 8), the primary goal for my PhD was to see if I could explore and validate some ideas that I think will push forward the state of the art, and form the foundation of AEG tools in the future. Those ideas are:
Real exploits are often relatively complex programs, with multiple distinct phases in which different tasks must be solved. Much like with ‘normal’ program synthesis, it is likely that different tasks will require different solvers. Also, by breaking the problem down we naturally make it easier to solve as long as solutions to distinct phases are composable. Thus, my first goal was to break the exploitation process down into distinct phases, with the intention of implementing different solvers for each. An interesting side effect of breaking the exploit generation task down into multiple, distinct, phases was it allowed me to integrate the idea of ‘lazy’ resolution of these phases, and solve them out of order. In practice, what this meant was that if a solver for an early stage was much more expensive than a later stage then my system allowed one to ‘mock’ out a solution to the early stage, and only come back to solve it for real once it was validated that having a solution for it would actually lead to an exploit.
Once exploit generation is broken down into multiple phases, we have decisions to make about how to solve each. Symbolic execution has powered the core of most exploit generation engines, but it has terrible performance characteristics. OTOH fuzzing has proven itself to be vastly more scalable and applicable to a larger set of programs. Why hadn’t fuzzing previously taken off as a primary component of of exploit generation? Well, if you treat exploit generation as a single, monolithic, problem then the state space is simply too large and there’s no reasonable feedback mechanism to navigate it. Greybox approaches that do input generation using mutation really need some sort of gradient to scale and a scoring mechanism to tell them how they are doing. Once we have broken the problem down into phases it becomes much easier to design feedback mechanisms for each stage, and the scale of the state space at each stage is also drastically reduced. My second goal was therefore to design purely greybox, fuzzing inspired, solutions for each phase of my exploitation pipeline. I purposefully committed to doing everything greybox to see how far I could push the idea, although in reality you would likely integrate an SMT solver for a few surgical tasks.
I knew it would be unlikely I’d hit upon the best solver for each pipeline stage at a first attempt, and it’s even possible that a real solution for a particular pipeline stage might be an entire PhD’s worth of research in itself. Thus it is important to enable one to swap out a particular automated solution for either a human provided solution, or an alternate solver. My third goal was then to figure out a way to enable multiple solvers to interact, be swappable, and to allow for a human in the loop. To enable this I designed a template approach whereby each stage, and a human exploit developer, could write and update exploits in a template language that further stages could understand and process. I wrote about what this looks like in practice here.
Alongside these goals I had to decide on a bug class and target software type to work with. Stack-based overflows had been done to death, so I decided to go with heap-based overflows which had received no attention. I also decided to target language interpreters (PHP and Python, in practice), as they’re ubiquitous and no exploit generation research had focused on them up to that point.
In the end the research was a lot of fun, and hopefully useful to others. I think the ideas of breaking down exploitation into multiple phases, using greybox solutions as much as possible, and using template-driven exploitation to integrate various solvers, or optionally a human, have real legs and are likely to be found in practical AEG engines of the future.
P.S. Thanks to my colleagues and friends that allowed me to bounce ideas off them, that read drafts, and that were generally awesome. Thanks as well to the anonymous reviewers of CCS, USENIX Security, and IEEE S&P. A lot of words have been written about the problems of the academic review process for both authors and reviewers, but on an individual and personal level I can’t but appreciate the fact that total strangers took their time to work through my papers and provide feedback.
Further Reading
Thesis – Contains all of my research, along with a lot of introductory and background material, as well as ideas for future work. One of the things I wanted to be quite clear about in my work was the limitations, and in those limitations it’s clear there’s plenty of scope for multiple more PhDs from this topic. In Section 1.2 I outline my assumptions, and by thinking about how to alleviate these you’ll find multiple interesting problems. In Section 6.1 I explicitly outline a bunch of open problems that are interesting to me. (Btw, if you do end up working on research in the area and would like feedback on anything feel free to drop me a mail).
At the upcoming ACM Conference on Computer and Communications Security (CCS) I’ll be presenting a paper on Automatic Exploit Generation (AEG), with the same title as this blog post. You can find the paper here. In the paper I discuss a system for automatically discovering primitives and constructing exploits using heap overflows in interpreters. The approach taken in the paper is a bit different from most other AEG solutions in that it is entirely greybox, relying on lightweight instrumentation and various kinds of fuzzing-esque input generation. The following diagram shows the stages of the system, and each is explained in detail in the paper.
Workflow diagram showing how Gollum produces exploits and primitives
In terms of evaluation, I used 10 vulnerabilities in the PHP and Python interpreters as tests, and provided these as input to Gollum for it to use in its search for primitives and to build exploits.
Exploit generation and primitive search results
There are three main takeaways from the paper that I think worth highlighting (see paper for details!):
1. AEG is a multi-stage process, and by breaking the problem into distinct phases it becomes reasonable to attack a number of those phases using a fuzzing-esque combination of lightweight instrumentation and relatively dumb input generation. Traditionally, AEG systems used symbolic execution as their main driver and, while there are some positives to this, it also encounters all of the scalability issues that one expects with symbolic execution. In a paper last year at USENIX Security, I showed how with lightweight instrumentation one could use the existing tests of an application, combined with a fuzzer, to discover language fragments that could be used to perform heap layout manipulation, as well as to allocate interesting objects to corrupt. In the upcoming CCS paper, I show how one can use a similar approach to also discover exploitation primitives, and in certain situations to even build exploits. It’s worth noting that in their paper on FUZE, Wu et al. take a similar approach, and you should check out their paper for another example system. My guess is that in the next couple of years fuzzing-driven exploit generation is likely to be the predominant flavour, with symbolic execution being leveraged in scenarios where its bit-precise reasoning is required and state-space explosion can be limited.
2. When automatically constructing exploits for heap overflows one needs a solution for achieving the desired heap layout and then another solution for building the rest of the exploit. In the CCS paper I introduce the idea of lazy resolution of tasks in exploit generation. Essentially, this is an approach for solving the problems of heap layout manipulation and the rest of the exploit generation in the reverse order. The reason one might want to do this is simple: in an engine where the process for achieving the heap layout can potentially take much longer than the one to create the rest of the exploit (as is the case in Gollum), it makes sense to check if it is feasible to produce an exploit under the assumption that the more difficult problem is solvable, and then only bother to solve it if it enables an exploit. Specifically, in the case of Gollum, I constructed a heap allocator that allows you to request a particular layout, then you can attempt to generate the exploit under the assumption the layout holds, and only later figure out how to achieve it once you know it enables the exploit.
I think this sort of idea might be more generally useful in exploit generation for other vulnerability types as well, e.g. in an exploit generation system for race conditions, one could have a solution that allows one to request a particular scheduling, check if that scheduling enables an exploit, and only then search for the input required to provide the scheduling. Such an approach also allows for a hybrid of manual and automatic components. For example, in our case we assume a heap layout holds, then generate an exploit from it, and finally try and automatically solve the heap layout problem. Our solution for the heap layout problem has a number of preconditions though, so in cases where those conditions are not met we can still automatically generate the rest of the exploit under the assumption that the layout problem is solved, and eventually the exploit developer can manually solve it themselves.
3. In last year’s USENIX Security paper I discussed a random search algorithm for doing heap layout manipulation. As you might expect, a genetic algorithm, optimising for distance between the two chunks you want to place adjacent to each other, can perform this task far better, albeit at the cost of a more complicated and time consuming implementation.
% of heap layout benchmarks solved by random search (rand) versus the genetic algorithm (evo)
At last year’s USENIX Security conference I presented a paper titled “Automatic Heap Layout Manipulation for Exploitation” [paper][talk][code]. The main idea of the paper is that we can isolate heap layout manipulation from much of the rest of the work involved in producing an exploit, and solve it automatically using blackbox search. There’s another idea in the paper though which I wanted to draw attention to, as I think it might be generally useful in scaling automatic exploit generation systems to more real world problems. That idea is exploit templates.
An exploit template is a simply a partially completed exploit where the incomplete parts are to be filled in by some sort of automated reasoning engine. In the case of the above paper, the parts filled in automatically are the inputs required to place the heap into a particular layout. Here’s an example template, showing part of an exploit for the PHP interpreter. The exploit developer wants to position an allocation made by imagecreate adjacent to an allocation made by quoted_printable_encode.
SHRIKE (the engine that parses the template and searches for solutions to heap layout problems) takes as input a .php file containing a partially completed exploit, and searches for problems it should solve automatically. Directives used to communicate with the engine begin with the string X-SHRIKE. They are explained in full in the above paper, but are fairly straightforward: HEAP-MANIP tells the engine it can insert heap manipulating code at this location, RECORD-ALLOC tells the engine it should record the nth allocation that takes place from this point onwards, and REQUIRE-DISTANCE tells the engine that at this point in the execution of the PHP program the allocations associated with the specified IDs must be at the specified distance from each other. The engine takes this input and then starts searching for ways to put the heap into the desired layout. The above snippet is from an exploit for CVE-2013-2110 and this video shows SHRIKE solving it, and the resulting exploit running with the heap layout problem solved. For a more detailed description of what is going on in the video, view its description on YouTube.
So, what are the benefits of this approach? The search is black-box, doesn’t require the exploit developer to analyse the target application or the allocator, and, if successful, outputs a new PHP file that achieves the desired layout and can then be worked on to complete the exploit. This has the knock-on effect of making it easier for the exploit developer to explore different exploitation strategies for a particular heap overflow. In ‘normal’ software development it is accepted that things like long build cycles are bad, while REPLs are generally good. The reason is that the latter supports a tight loop of forming a hypothesis, testing it, refining and repeating, while the former breaks this process. Exploit writing has a similar hypothesis refinement loop and any technology that can make this loop tighter will make the process more efficient.
There’s lots of interesting work to be done still on how exploit templates can be leveraged to add automation to exploit development. In automatic exploit generation research there has been a trend to focus exclusively on full automation and, because that is hard for almost all problems, we haven’t explored in any depth what aspects can be partially automated. As such, there’s a lot of ground still to be broken. The sooner we start investigating these problems the better, because if the more general program synthesis field is anything to go by, the future of automatic exploit generation is going to look more like template-based approaches than end-to-end solutions.
I was lucky enough to attend a Dagstuhl seminar titled “Bringing CP, SAT & SMT Together” earlier this week, and learned about some really cool work I hadn’t previously heard of, especially in the realm of constraint satisfaction and optimization. There were plenty of other of great talks and discussions, but below are the projects I made a note to play around with.
MiniZinc
“MiniZinc is a free and open-source constraint modeling language.
You can use MiniZinc to model constraint satisfaction and optimization problems in a high-level, solver-independent way, taking advantage of a large library of pre-defined constraints. Your model is then compiled into FlatZinc, a solver input language that is understood by a wide range of solvers.“
There are even a couple of Coursera courses on the topic.
“Unison is a simple, flexible, and potentially optimal tool that performs integrated register allocation and instruction scheduling using constraint programming as a modern method for combinatorial optimization.“
Blog post by Mate Soos (author of cryptominisat), with code:
“Approximate model counting allows to count the number of solutions (or “models”) to propositional satisfiability problems. This problem seems trivial at first given a propositional solver that can find a single solution: find one solution, ban it, ask for another one, ban it, etc. until all solutions are counted. The issue is that sometimes, the number of solutions is 2^50 and so counting this way is too slow. There are about 2^266 atoms in the universe, so counting anywhere near that is impossible using this method.“