In the previous post I advocated for building systems that combine static and dynamic analysis for performance optimisation. By doing so, we can build tools that are much more useful than those focused on either analysis approach alone. In fact, for many static analyses it’s likely that the difference between being useful at all and not so, is whether or not it’s combined with a profiler. As an example, continuous profiling can gather information on the hottest code paths in production environments, and this can be used to rank the output of the static analysis. A developer can then focus their efforts on the most important findings. This minimises the time wasted due to false positives, or unimportant true positives, from the static analysis. Conversely, static analysis can be used to provide further context on the output of continuous profiling and make its results more actionable, such as suggesting why a particular function may be hot, or suggesting potential optimisations.
In the previous post also I outlined a trivial-but-very-effective combination of analyses, in which the Top N most expensive functions identified by continuous profiling are piped into a service that checks library and function names against a list of known faster replacements, allowing a developer to optimize their application with zero code changes. e.g. swapping jemalloc for libc malloc, zlib-ng for zlib, orjson for Python’s stdlib JSON etc.
In this post we’re going to go deeper, with a static analysis that actually looks at the application’s code. When I started thinking about combinations of analyses for performance optimisation, I didn’t find much in the way of off-the-shelf static analyses that I could just use. So, I decided to build my own. We’re going to try and answer the question: can we use static analysis to find C/C++ code patterns that lead to sub-optimal machine code being emitted by the compiler?
I’ll first describe a particular code pattern that can lead to the compiler emitting unnecessary memory reads, and failing to auto-vectorise loops. When these patterns exist they can lead to functions being 10-20x or more slower than they otherwise could be. I’ll show how we can build CodeQL queries to find the patterns, and how we can modify the code to allow the compiler to auto-vectorise. I’ll then discuss results of applying the queries to a few code bases, lay out some issues that arise, and detail some potential future work and open questions.
CodeQL
CodeQL allows you to write queries in a declarative object-oriented language, and apply those queries to a codebase that has been converted into a relational representation in a database. In other words, it provides a relatively easy-to-work-with query language for finding interesting patterns in code. Typically it is used in the security space for bug hunting. From a vulnerability hunter’s point of view CodeQL provides a relatively unique and powerful capability for a static analysis tool. Existing static analysis tools (Coverity, the clang static analyser etc.) encode checks for common vulnerability patterns, but by virtue of the fact that these very tools are part of the toolbox of many software developers, and the fact that trivial overflow patterns are less and less likely to make it through modern QA, such analysers aren’t particularly helpful for a vulnerability hunter. For this reason, and others, static analysis by and large does not have a great reputation amongst people interested in finding exploitable software flaws. By allowing one to conveniently encode arbitrary patterns and search for them in a database, CodeQL enables “variant analysis”, i.e. searching for variations of a given bug in the same codebase, or a new codebase. This turns out to be a fruitful way of finding security vulnerabilities. As of yet CodeQL hasn’t seen any use that I’m aware of in the realm of detecting performance issues, but its flexibility makes it an excellent candidate technology for any property that can be encoded as predicates over an abstract syntax tree.
The Inconveniences of Type Aliasing in C/C++
In Optimising an eBPF Optimiser with eBPF I discussed searching for performance improvements in a program synthesis engine. One of the optimisations I made was to modify the code to allow the compiler to auto-vectorise a series of very hot loops which looked as follows:

Under the hood, a std::vector<bool> has some properties that mean the loops cannot be auto-vectorised. See the post I just mentioned for details, but in short: we needed to replace std::vector<bool> with a vector of something other than a bool. The original something that I chose was a uint8_t but, to my surprise, instead of getting out a nicely unrolled and vectorised loop, what I got was this:

The compiler has generated code that on each iteration of the loop loads the source and destination pointers from [r12] and [rbx+0xa8], and thus it cannot auto-vectorise. I eventually tracked down the issue with the help of this post by Travis Downs. The problem is type aliasing. In C/C++, the char type (and its kin, such as uint8_t) can alias every other type. On a write to memory through such a type the compiler has to assume that it may have modified any other heap-based memory location, even if that location has an entirely different type (such as the data pointers contained in the source and destination vectors in the above example). Because of this, in the above example, the compiler must assume [r12] and [rbx+0xa8] could have been modified by the write to [rdx+rax] and therefore cannot safely auto-vectorise the loop as it needs to reload these values after each write.
In many situations, having to reload a value from memory is not the end of the world, but in the context of loops in particular the issue can lead to drastically worse code being generated by the compiler than would otherwise be possible. In Travis’ blog post he shows a particularly pathological example where the issue leads to code that is 20x slower than it could be.
There are a variety of ways to fix this ‘problem’. Where possible, replacing the uint8_t/char type with a char8_t will solve it. The char8_t type, introduced in C++20, does not have the aliasing issue that char does. If C++20 cannot be used, and switching to some other wider primitive type is not reasonable, then another option is to try and lift any code that requires a load from memory out of the loop. For simple code this can be straightforward e.g. lifting an access to the size() attribute of a vector out of the loop condition, to before the loop. However, for larger, more complex loops, this can quickly become infeasible and one can be stuck with accepting the overhead of unnecessary memory loads due to type aliasing.
Searching for Aliasing Writes
Our goal is to build a query that will find patterns in code whereby, due to writes through aliasing types, the compiler is generating loads from memory that we know are unnecessary. Lets begin by describing at a high level what we are looking for.
What we want to search for a sequence of code which looks like:
- A load from memory through an expression X, where X denotes a memory location. e.g. X may be of the form
*a,a[i],*(a+i)etc. - Followed by a write through an aliasing type, such as a char
- Followed by a load from memory through X, such that none of the components of the expression X have been modified since step (1). e.g. if the expression X is
*(arr+i)then we require that botharrandihave not been modified. If they have been modified then the compiler would need to emit another load from memory, regardless of the write through the aliasing type.
At a glance, this seems like a fairly easy set of properties for a static analyser to match on. We won’t worry about reasoning across function boundaries (although we will handle inlined functions), and each property can be expressed as a syntactic predicate on an AST.
In the following examples the code marked as [1], [2], and [3] correspond to items 1, 2 and 3 in the above list.
The above pattern will match a straight-line sequence like the following:
// glib-2.0/glib/gstring.h
static inline GString*
g_string_append_c_inline (GString *gstring,
gchar c)
{
if (gstring->len + 1 < gstring->allocated_len) // 1
{
gstring->str[gstring->len++] = c; // 2
gstring->str[gstring->len] = 0; // 3
}
else
g_string_insert_c (gstring, -1, c);
return gstring;
}
Here [1] marks the first load from memory via the the read of gstring->len, [2] marks the write through the aliasing type via the write of c into gstring->str, and [3] marks the second read via the read of gstring->len again. Due to [2] the compiler is forced to generate a second load of gstring->len at [3] although we can see that the write at [2] cannot impact it, and the value could have been stored in a register and reused . In fact, the write through the aliasing type results in two extra reads from memory here, as on part [3] the compiler not only has to reload gstring->len but also gstring->str. You can view the assembly produced for this on Compiler Explorer.
The pattern will also match slightly more complex loops such as:
// tesseract/src/classify/adaptmatch.cpp
for (unsigned id = 0; id < templates->NumClasses; ++id) { // 1,3
int font_set_id = templates->Class[id]->font_set_id;
const FontSet &fs = fontset_table_.at(font_set_id);
for (auto f : fs) {
const Shape &shape = shape_table_->GetShape(f);
for (int c = 0; c < shape.size(); ++c) {
if (char_norm_array[shape[c].unichar_id] < pruner_array[id]) {
pruner_array[id] = char_norm_array[shape[c].unichar_id]; // 2
}
}
}
}
(Here [1] and [3] mark the first and second loads of templates->NumClasses, while [2] marks the write to pruner_array which has type uint8_t*. There are actually several other values that must be reloaded from memory in this example due to the aliasing write, not just templates->NumClasses.)
The pattern we have described matches not just the outermost loop above, but also the innermost loop on line 7, as shape is a vector and the call to the size() function will be inlined.
// tesseract/src/classify/adaptmatch.cpp
for (int c = 0; c < shape.size(); ++c) { // 1,3
if (char_norm_array[shape[c].unichar_id] < pruner_array[id]) {
pruner_array[id] = char_norm_array[shape[c].unichar_id]; // 2
}
On each iteration of the loop the size of the vector will be unnecessarily reloaded due to the write at [2].
To bring these examples full circle, lets actually make the change required to remove the aliasing issue. Jumping back to the glib example, the original version can be found on Compiler Explorer here and the optimised version (in which we replace the char type with the C++20 char8_t type) can be found here. Below, the original is on the left, and the version using char8_t is on the right.


In the original, lines 79 to 81 correspond to gstring->str[gstring->len] = 0. The rdi register points to the GString structure, with the pointer to the string at offset 0 and the length at offset 8. We can see that the compiler has emitted code to load both from memory due to the write on line 78 which it must consider as potentially aliasing with the internals of the GString object. In the optimised version using char8_t we can see that the compiler has not had to worry about the aliasing write, and has generated a single instruction for this line of code: line 78. This instruction reuses the string pointer and string length which were previously loaded into rcx and rax.
In conclusion, we have a pattern we can describe in plain English to find a code pattern, and we have evidence that if we can find such a code pattern then we can make trivial changes that may enable the compiler to emit more efficient code. Lets now move onto building CodeQL queries to automate the search for this pattern.
CodeQL Queries to Find Aliasing Writes
What we are searching for is conceptually very simple: two loads from memory, with a write through an aliasing type in between. The easiest part of this to express in CodeQL is the write, which looks as follows (I’ve put all the CodeQL queries we’ll build in this repository, and this sample can be found here):
predicate isMemCharWriteExpr(Expr e) {
exists(AssignExpr a, Expr lval |
a = e.(AssignExpr) and // A
lval = a.getLValue() and
lval.getType().stripType() instanceof CharType and // B
(
lval instanceof PointerDereferenceExpr or // C
lval instanceof ArrayExpr or // C
lval instanceof OverloadedArrayExpr // C
)
)
}
This predicate returns true if the expression passed to it matches “an assignment expression (A), in which the lvalue has a character type (B) and the lvalue is a pointer dereference, array expression or overloaded array expression (C)”. We can immediately see here that expressing an assembly level concept like “a read from memory” requires us to enumerate the C/C++-level syntactic constructs that we think may produce such assembly. This has the potential to introduce both false positives and false negatives. It will also result in our queries being quite verbose, even though in natural language we can concisely express the properties we want to match on.
The increment and decrement operators can also result in a write to memory, (e.g. v[x]++), so our predicate must also account for those. They can be handled in a similar manner to assign expressions, so for brevity I have not presented that part of the query here, but you can find the full predicate here on Github.
We next need a way to match against C/C++ code that we think will produce loads from memory with the properties that we outlined as item 1 and item 3 in the sequence that we are after. For this, we need to construct a query which matches two expressions in the same function that will result in a load from memory, where in theory the compiler could cache the result of the first load in a register and reuse it in the second load, if it weren’t for the intervening write through the aliasing type. There are a few different syntactic constructs in C that may result in a load from memory. We could have:
- An array expression, e.g.
x = array[offset] - A pointer dereference, e.g.
x = *ptr - A pointer field access, e.g.
x = ptr->val
Alongside these we also have the possibility that functions that result in memory reads can be inlined, e.g. the vector size() function.
The query implementation for finding code patterns that involve array expressions, pointer dereferences and pointer field accesses are all fairly similar, so I will just walk through the one for pointer field accesses here (found here on Github, with the helper functions here). A pointer field access consists of something like base->field. In the following code, a1 represents our first memory access, w represents the write to memory through the character type, and a2 represents our second memory access.
from
Expr w, PointerFieldAccess a1, PointerFieldAccess a2, Variable baseVar
where
(
isMemCharWriteExpr(w) and // [1]
// Sequence of execution is a1 -> w -> a2
a1 = w.getAPredecessor+() and // [2]
w = a2.getAPredecessor+() and // [2]
baseVar = a1.getQualifier().(VariableAccess).getTarget() and // [3]
// Assert that a1 and a2 use the same base pointer
baseVar = a2.getQualifier().(VariableAccess).getTarget() and // [3]
// Assert a1 and a2 access the same field in the struct
a1.getTarget() = a2.getTarget() and // [4]
// Eliminate cases where the variable holding the base pointer is modified
not exists(AssignExpr redef | // [5]
redef = a1.getASuccessor+()
and redef = a2.getAPredecessor+()
and redef.(AssignExpr).getLValue().(VariableAccess).getTarget() = baseVar
)
// Further cases here to eliminate things like increments, redeclarations etc
...
)
select a1.getLocation().getFile().getBaseName(), a1.getLocation().getStartLine(), a1, w, a2, baseVar
- We begin by passing the write expression
wto our predicate to assert that it is a write of a character type that will result in a memory dereference - We then assert the ordering of our three expressions, namely that
a1comes beforewwhich comes beforea2 - We need to get the
basevariable frombase->ptrso we can later make assertions on it. We extract it froma1and assign it tobaseVar, and then also assert thata2makes use of the same base variable. While this might look like we are assigning something tobaseVarand then immediately overwriting it, remember that this is a declarative query language, not an imperative one. We are stating thatbaseVarequals two things, therefore they must be the same. - We also need to assert that the field accessed is the same at
a1anda2 - Finally, we specify that between
a1anda2thebaseVarhas not been modified. The case above specifies that there are no assignment expressions betweena1anda2where the lvalue is the base variable. In the full query we also handle a few other ways that the base variable might be modified.
And that’s it! This query, and the similar ones for pointer dereferences and array expressions, are sufficient to find the patterns we’re looking for. It will find them in both straight-line sequences of code and in loops. As presented, these queries operate in a scope that is local to a single function. They won’t find cases where the memory access results from a call to an inlined function, such as vector.size(). In the next section I’ll show how we can deal with that scenario, as it is necessary in order to detect inlined function calls in loop conditions, which is a productive source of the sorts of memory accesses we are searching for.
Finding Inlined Memory Accesses in Loop Conditions
A common source of memory loads that meet our requirements are loads behind an inlined function call in a loop condition, e.g. something that checks the size of a vector, such as for (i = 0; i < vector.size(); i++). We could modify our existing queries that search for two memory accesses with an intervening aliasing write, as they are generalisations of the case of a loop condition containing a memory access and an aliasing write within that loop body. However, one lesson I’ve learned with CodeQL is that it’s often easier to build queries for exactly what you have in mind and later generalise if necessary. Premature generalisation can lead to overly complex queries that are difficult to debug, and prone to both false positives and false negatives. Starting with a concrete example, then generalising if necessary, has generally proven to be a better strategy.
A concrete example of what we wish to find is:
void vector8_inc(std::vector<uint8_t> &v) {
for (size_t i = 0; i < v.size(); i++) {
v[i]++;
}
}
So, we want a loop in which:
- The condition has a call to an inlined function that results in a memory access, and
- There is a write to memory within the body of the loop.
The CodeQL query to express this begins as follows:
from Loop l, Expr w
where
// The loop condition accesses memory in some way
loopConditionAccessesMemory(l)
// And the loop contains a character-write expression
and isMemCharWriteExpr(w) // [1]
and w.getEnclosingStmt().getParentStmt*() = l.getStmt() // [2]
select l.getLocation().getFile().getBaseName(), l.getLocation().getStartLine(), l, w
The write-to-memory part is handled in the same manner as our earlier queries via isMemCharWriteExpr [1], and we add the requirement that the write expression is inside the loop [2]. loopConditionAccessesMemory is the predicate we’ll use to find loop conditions that either access memory directly or call an inlined function that does so (the query contents found here, with most of the functionality in helpers found here on GitHub). It looks as follows:
// Returns true if the loop condition contains a function call that we think will
// result in a memory access.
predicate loopConditionAccessesMemory(Loop l) {
exists(FunctionCall funcCall, Function func |
funcCall = l.getCondition().getAChild() // [1]
and func = funcCall.getTarget()
and func.isInline() // [2]
and allCalleesAreInline(func) // [3]
and hasMemoryAccess(func) // [4]
)
}
We want a loop condition containing a function call [1] to an inline function [2] that itself only calls other inline functions [3] and that either it, or its callees, contain a memory access [4]. The predicates that check [3] and [4] are recursive, and look as follows:
// Recursive predicate. Returns true if all functions called from this function
// are inline, as are their callees, and so on.
predicate allCalleesAreInline(Function func) {
not exists (Function called | // [1]
(not called.isInline() or not allCalleesAreInline(called)) // [2]
and called.getACallToThisFunction().getEnclosingFunction() = func // [3]
)
}
allCalleesAreInline asserts that there are no functions [1] that are called from the current function [3], such that the called function is not inline or it calls any functions that are not inline [2].
// Recursive predicate. Returns true if this function, or any function it calls,
// contains an expression that we think will result in a memory access.
predicate hasMemoryAccess(Function func) {
// The function contains either a PointerFieldAccess (e.g. this->x) or an
// implicit access via the this pointer
exists (PointerFieldAccess pfa | pfa.getEnclosingFunction() = func) // [1]
or exists (ImplicitThisFieldAccess itfa | itfa.getEnclosingFunction() = func) // [1]
// Or, it calls a function that meets the above properties
or exists (Function called | // [2]
called.getACallToThisFunction().getEnclosingFunction() = func
and hasMemoryAccess(called))
}
hasMemoryAccess asserts that this function contains an expression that may produce a memory access [1], or that it calls a function that contains a memory access [2].
Alternatively, instead of building the predictaes to look for any inline function with memory accesses, we could have gone with a more hacky variant and matched specifically on calls to functions with names like “size”, “length” and whatever other functions we think might have the properties that we want. In fact, I did this in the first version of the query, and it does work, with one important caveat. For the curious, that predicate looked as follows:
// Find a loop with a call to vector.size() (or some equivalent) in the condition
predicate loopConditionAccessesMemory(Loop loopCond) {
exists(Expr funcCall, Function func, string fname |
funcCall = loopCond.getCondition().getAChild()
and funcCall instanceof FunctionCall
and func = funcCall.(FunctionCall).getTarget()
and func.isInline()
and fname = func.getName()
and (
fname = "size" or fname = "len" or fname = "count" or fname = "length"
or fname = "begin" or fname = "end" or fname = "rbegin" or fname = "rend"
)
)
}
While functional, this may result in false negatives when we fail to predict the custom function names used in a particular project. In C++ codebases, custom inlined accessor functions that appear in loop bounds are quite common. E.g. the get_height function in the following loop header is found by the more complex predicate I showed above, but not by the simplified one that just matches on function names.
for (uint32_t y = 0; y < img.get_height(); y++)
Results & Analysis
In order to run CodeQL queries on a project you need a CodeQL database. Such databases are automatically built for public projects on Github and then hosted on lgtm.com. I picked a few C++ projects from there with the goal of answering the following questions:
- Do the queries work at all? With static analysis I’m always mildly afraid that when applied to real world projects I’ll either be drowned in false positives or get no results at all due to an analyser either dying or running forever. So, first I wanted to see if I can actually get a result set in a reasonable amount of time, with a reasonable false positive to true positive ratio.
- For the true positives, can we optimise the code so that the aliasing write is either removed or the code is restructured so that its impact is limited. If so, what sort of performance improvement do we get as a result?
- How, if at all, would this analysis fit into a real development workflow or CI/CD pipeline?
Let’s first start with some concrete examples of true positives found by the analysis.
Sample Findings
Bitcoin
The codebase I started with was bitcoin. The queries to find accesses resulting from pointer dereference expressions (PDE) and pointer field accesses (PFA) mostly turned up false positives. There were a few true positives, but they were in straight-line sequences of code and the sort of thing where even if the aliasing write was removed it might save on a single memory access on each function invocation. So, not something I wanted to even consider looking into unless we were really desperate for results! Meanwhile, the Array Expression (AE) query turned up no results at all. Maybe we would end up desperate after all 😉
However, the query searching for memory accesses in loop conditions (LC) came to the rescue finding a bunch of interesting true positives. I’ll get into more detail in the analysis at the end of the post, but to answer any of you wondering “Why was the LC query successful when the others were not?”, empirically it turns out the sweet spot for this sort of analysis is code that has two properties:
- It’s a loop, meaning any redundant memory accesses we remove will be saved on every loop iteration, and not just once.
- The loop condition accesses some class attribute, meaning at least one redundant access will be emitted in order to load that value. This access is often behind an inlined function, which the LC query will handle correctly, while the others do not.
Onto the findings …
bech32.cpp bech32::ExpandHRP
The bech32::ExpandHRP function is found in src/bech32.cpp.
/** Expand a HRP for use in checksum computation. */
data ExpandHRP(const std::string& hrp)
{
data ret;
ret.reserve(hrp.size() + 90);
ret.resize(hrp.size() * 2 + 1);
for (size_t i = 0; i < hrp.size(); ++i) { // 1
unsigned char c = hrp[i];
ret[i] = c >> 5; // 2
ret[i + hrp.size() + 1] = c & 0x1f; // 2
}
ret[hrp.size()] = 0;
return ret;
}
At [1] we have a call to the size() function of std::string, which will read the length of the string from memory. Then at [2] we have two writes to the memory that is backing the ret variable. ret has the data type, which is just a typedef for std::vector<uint8_t>. While ret itself lives on the stack, the call to reserve will result in a call to new which will allocate space on the heap for its contents. If this were not the case, and the contents remained on the stack then the aliasing write would not be a problem as the compiler could safely assume that the writes to the vector on the stack would not interfere with the contents of hrp. However, due to the reallocation on the heap and the fact that the uint8_t is essentially a char, the compiler must assume that at [2] the writes may update the length of the string hrp. It will therefore generate code to load that value from memory at the head of the loop on each iteration.
It gets worse. To see why, lets look at the assembly generated.
The copy loop generated by clang 13.0.1 (-O3 -march=skylake -std=c++20) is as follows (you can find it on Compiler Explorer here):
.LBB0_15:
mov rcx, qword ptr [rbx] // A. Load the string contents pointer from hrp
movzx ecx, byte ptr [rcx + rax] // B. Load next byte from the string
mov edx, ecx
shr dl, 5
mov rsi, qword ptr [r14] // C. Load the vector contents pointer from ret
mov byte ptr [rsi + rax], dl // D. Write ‘c >> 5’ to vector contents
and cl, 31
mov rdx, qword ptr [r14] // E. Load the vector contents pointer from ret
add rdx, qword ptr [rbx + 8] // F. Add hrp.size() to contents pointer
mov byte ptr [rax + rdx + 1], cl // G. Write ‘c & 0xff’ to vector contents
inc rax
mov rcx, qword ptr [rbx + 8] // H. Check ‘i < hrp.size()’
cmp rax, rcx
jb .LBB0_15
Both the string variable hrp and the vector variable ret contain data pointers which refer to their contents, and even though we know that these pointers in hrp and ret cannot change due to the writes performed in the loop (nor can the length of hrp) the compiler has to generate loads for these pointers (and the length) after each write to ret. The redundancy is most obvious at [E] where, due to the write at [D], the compiler is forced to reload the value from ret (*r14) that it had just loaded at [C].
You may be wondering why the compiler is forced to reload the pointer from ret at all, even in the presence of the aliasing write, given that ret itself is stack allocated and should be provably distinct from the writes to the heap. The answer can be found by looking at the link to Compiler Explorer above. Due to C++’s Return Value Optimisation/Copy Elision, the pointer to be used for ret is passed to ExpandHRP by the caller in the rdi register, then moved to r14, rather than being stack allocated and then copied out upon the return. See here for more details. While normally a good thing, this has the downside in this case that the compiler can no longer assume that the writes do not alias with the memory that backs ret.
In summary, we end up with 6 loads from memory on each iteration of the loop, when in reality we need just the one to load the byte of data we wish to operate on. The necessity of these loads also means that the compiler is prevented from vectorising the loop. If the pointers and size were guaranteed to be stable during iteration of the loop then it could copy large chunks of data, instead of single bytes at a time. But it can’t.
So how do we fix it?
Turns out it’s fairly straightforward: define data as a std::vector<char8_t> (C++20 only) instead of std::vector<uint8_t>, thus eliminating the aliasing issue. The compiler no longer needs to reload data pointers or the source string size, and all going well we should get a nicely vectorised loop. The Compiler Explorer result is here and is as expected.
The following graph shows the benchmark results for the original versus the optimised example, and varying the input size.

Not bad for a four character change! At 32k input bytes the optimised version is 12x faster than the previous version! In practice, it seems the maximum input length that can reach ExpandHRP in the bitcoin codebase is 90. At this size the optimised version is 2.6x faster, so still quite a nice improvement.
i2p.cpp SwapBase64
Another result from bitcoin is found in src/i2p.cpp. The SwapBase64 function looks as follows:
std::string orig_SwapBase64(const std::string& from)
{
std::string to;
to.resize(from.size());
for (size_t i = 0; i < from.size(); ++i) { // 1
switch (from[i]) {
case '-':
to[i] = '+'; // 2
break;
case '~':
to[i] = '/'; // 2
break;
case '+':
to[i] = '-'; // 2
break;
case '/':
to[i] = '~'; // 2
break;
default:
to[i] = from[i]; // 2
break;
}
}
return to;
}
As before we have a loop in which the size of a string is used in the loop condition [1] and a series of writes to character types within that loop [2]. In total there are three “unnecessary” loads from memory that take place within the loop, due to the writes. The string size in the loop condition, as mentioned, but also the data pointers for to and from.
C++20 comes with the std::u8string type that is the string equivalent of char8_t and does not have the aliasing issue, so we can fix the problem by replacing std::string with std::u8string. Unfortunately, by the nature of the code in the body of the loop, on this occasion auto-vectorisation cannot take place. Instead, we end up with a loop that simply has to do three fewer reads from memory. A Compiler Explorer session with the original and the updated version can be found here. The primary differences are shown in the following code snippets.
In the first snippet we have the head of the unoptimised version. Line 45 is the head of the loop. On line 48 the destination pointer is loaded, on line 51 the string size is loaded, and on line 54 the source pointer is loaded. This occurs on each iteration of the loop.

In the second snippet we see the same code, but for the optimised version. The only memory accesses are the necessary ones, i.e. the write to memory on line 158 and the read from memory on line 163.

Running both versions over strings from size 8 to 16M (increasing in powers of 8) we get the following:
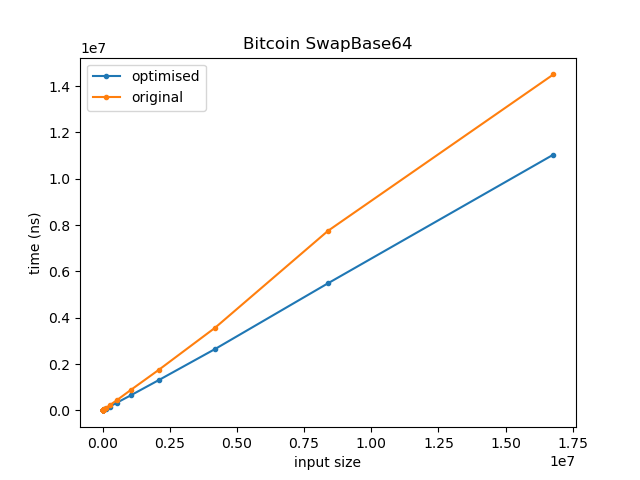
For clarity, the graph of the lower 32k looks as follows:
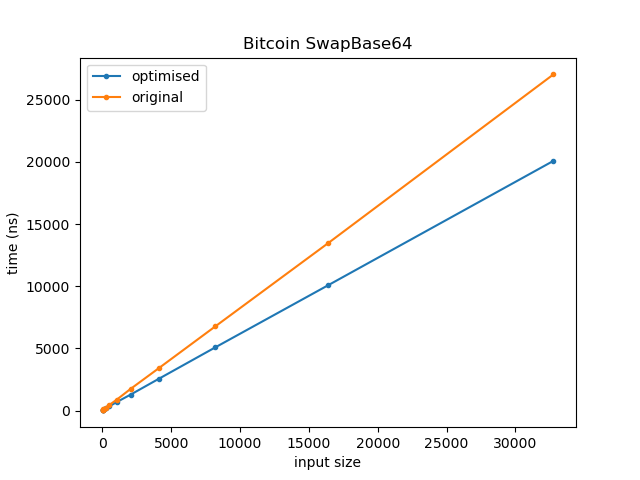
The optimised version executes approximately 63% of the instructions as the unoptimised version, and is on average 1.28x faster.
Monero
The next example comes from the Monero project. By this stage, I had come to the conclusion that the query focused on loop conditions had, by far, the best reward to effort ratio. The others tended to have a much worse false positive/true positive ratio, and require a lot more reasoning in order to distinguish true positives from false positives. The examples that they found also tended to be harder to mitigate in order to fix the issues.
bulletproofs.cc rct::bulletproof_PROVE
rct::bulletproof_PROVE is found in src/ringct/bulletproofs.cc. It contains a loop that follows a similar pattern to what we have seen so far.
Bulletproof bulletproof_PROVE(const std::vector<uint64_t> &v, const rct::keyV &gamma)
{
CHECK_AND_ASSERT_THROW_MES(v.size() == gamma.size(), "Incompatible sizes of v and gamma");
// vG + gammaH
PERF_TIMER_START_BP(PROVE_v);
rct::keyV sv(v.size());
for (size_t i = 0; i < v.size(); ++i)
{
sv[i] = rct::zero();
sv[i].bytes[0] = v[i] & 255;
sv[i].bytes[1] = (v[i] >> 8) & 255;
sv[i].bytes[2] = (v[i] >> 16) & 255;
sv[i].bytes[3] = (v[i] >> 24) & 255;
sv[i].bytes[4] = (v[i] >> 32) & 255;
sv[i].bytes[5] = (v[i] >> 40) & 255;
sv[i].bytes[6] = (v[i] >> 48) & 255;
sv[i].bytes[7] = (v[i] >> 56) & 255;
}
PERF_TIMER_STOP_BP(PROVE_v);
return bulletproof_PROVE(sv, gamma);
}
At a glance, this loops like a simple copy loop, for which the compiler should be able to generate assembly which performs all 8 assignments to sv[i].bytes at once. However, as the bytes array has a char type, after each assignment the compiler must generate code to reload several previously loaded values. The resulting assembly looks as follows, with most of the memory reads being unnecessary:

Resolving the issue is straightforward. As before we can simply change the type of the bytes array to be char8_t. With this change the compiler generates the following for the loop body:

As desired, we are now performing all 8 assignments in one go. The performance improvements are as you’d expect. The following graphs time on the y-axis against inputs with sizes in the range 2^6 to 2^14.
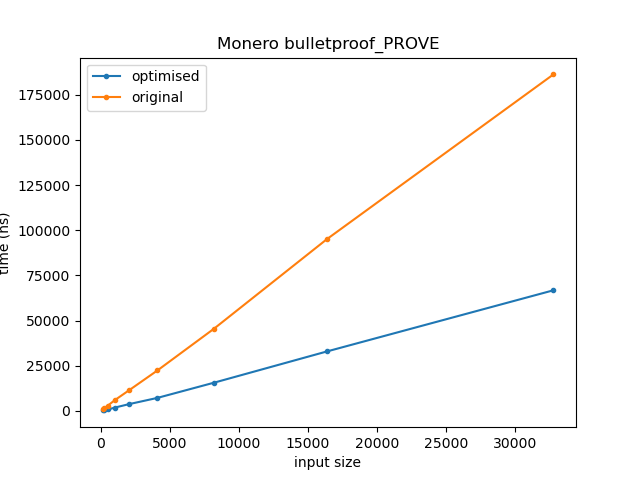
I’m unsure how big the keys used for this function are in reality, but the speedup is around 3-4x for sizes in the range 128 to 8192.
I think by now the sorts of patterns this approach tends to pick up should be clear, so let’s move on to answer the original questions I set out at the start of this section.
Analysis
The high level questions I had in mind at the start were as follows:
Q1. Do the queries actually work at all? Meaning, can we get a result set in a reasonable amount of time, with a reasonable false positive to true positive ratio.
Yes, the queries work, but there are some important details which I’ll get to in a minute.
Even on larger codebases the total query execution time is typically not more than a few seconds. I haven’t gathered precise numbers on the true positive to false positive ratio due to time constraints, but empirically I would say it is ‘reasonable’. To find the sort of patterns we are looking for it is sufficient to do syntactic pattern matching within functions, so we avoid the need to perform the types of semantic analysis that tend to lead to false positives. Many of the false positives are due to flaws in my queries that could probably be fairly trivially fixed by someone better at CodeQL than me.
There are a few important notes to be added here.
Detail #1: The Loop Condition (LC) query is much less prone to false positives than the other queries that are more generic, and has a much better effort-to-reward ratio. It is worth discussing why this is, as the reasons are helpful in understanding the limitations of using CodeQL to hunt for performance issues in general. By “effort-to-reward ratio”, I mean the effort one must undertake to both triage a finding into true positive versus false positive, plus the effort required to fix the found aliasing issue, versus the reward in terms of the speed-up of the code as a result of fixing this issue.
The LC query looks for loops that read from memory in their loop condition and also have a write through an aliasing type in their loop body. Alongside these properties, there are a couple of others that, for the sake of brevity I did not go into when presenting this query earlier. They are that it requires that the loop body is linear (no branching), and if there are any function calls then the called function is inline (and recursively any such inline function is also linear, and only calls other inline functions). The reason for focusing on loops without branching is that a true positive means a vectorised alternative is more likely attainable, and the reason for avoiding loops with non-inlined function calls is that quite often in such situations the compiler will generate code to reload values from memory after the function call, even if we remove the aliasing write from the loop. The query containing these extra restrictions can be found here.
So why does the LC query result in fewer false positives, and have true positives that have better performance improvements? The latter is straightforward: since we’re looking at loops, by their nature they execute repeatedly and thus any improvement we find is magnified in comparison to straight-line code. Since we’ve restricted the loop body in various ways there’s also a chance that when we find a loop that matches our pattern it may be vectorisable, or at least that the improvements that we make will be significant in comparison to whatever else is in the loop. Due to the fact that these loop bodies tend to be small, the effort required to determine what changes are necessary to fix the aliasing issue is also usually low.
As for why the LC query has fewer false positives, again this comes down to the restrictions that we place on the loop body for matching results. We are pattern matching at the source code level, but fundamentally the properties that we care about are patterns over assembly code. Why is this important? Well, our queries describe patterns in source code that we think should result in assembly code that results in “unnecessary” reloads of data from memory. However, the compiler’s optimisation passes are complex and there are a bunch of different things that may result in a value being cached in a register or spilled to memory. Some of these aspects can be captured as syntactic patterns, while others cannot (e.g. register spilling decisions or even minor compiler bugs), and some are situationally dependent, or even compiler dependent. We can therefore have “true positives” that are true in the sense that at the source code level the code does match the pattern we are after, but, despite this, even if we were to remove the aliasing write we would still not get more optimised code that does not contain the “unnecessary” load due to aspects of the surrounding code and the decisions the compiler makes as a result.
The impossibility of capturing the compiler’s internal reasoning in terms of CodeQL queries means that the more code that is spanned by a finding, from the first load of a value to its later reuse, the more likely it is that in between those points will be something other than the aliasing write that would cause the compiler to have to reload the value anyway, even if we remove the write. The other queries, besides LC, have fewer restrictions and thus tend to span code blocks that are larger and more expressive, and thus have more of these sorts of “false positive” findings where removing the aliasing write does not lead to any benefit. We could of course add the restrictions from the LC query to the other queries, to require linear code and no function calls. This would probably help with the false positives. However, I haven’t bothered to do this as I don’t think these other query types are likely to have a reasonable effort-to-reward ratio, even with this change. As mentioned, the effort to reward ratio is much higher with loops so I think that’s likely where the sweet spot is for this type of analysis. If I wanted to pursue this further, I would put my time into expanding the types of syntactic patterns that match loads from memory in the loop condition, rather than trying to make the more generic queries more usable.
Detail #2: As the setup for my test was “get some C/C++ codebases and run the queries”, I have no ground truth. Therefore we have no real clue what the false negative rate is. Above, I have argued for the usefulness of the LC query, partially due to the positive effect of the restrictions it imposes on the ratio of true positives to false positives. It’s unlikely this is a free lunch, and my guess is there are loops that have the aliasing issue that we are looking for, but that are excluded by the LC query. I haven’t come across any, but I also haven’t looked. If you happen to find one, let me know.
Detail #3: I also ran the queries on a few C codebases, namely the Python and PHP interpreters, and the Linux kernel. In these codebases there were some true positives, but none which would have any meaningful impact on the function’s performance were they fixed.
Q2: For the true positives, can we optimise the code so that the aliasing write is either removed or the code is restructured so that its impact is limited. If so, what sort of performance improvement do we get as a result?
In short, yes, we can, and the performance gain depends on the nature of what the code is doing. This is mostly answered above, but to restate the most relevant part: it pays to put one’s efforts into triaging results that are likely to have a significant pay off if they are true positives. Loops, in other words. Alternatively, if one has functions that are called a lot, that would fit the bill for the same reason.
For the more generic queries that did not focus on loops, I found trying to both triage and optimise them to be a painful process for the reasons mentioned in Caveat #1 of Q1. There was often a significant amount of code in between the first load from memory and the second, and trying to reason about whether the compiler will have the need to reload at the second point, even if we remove the aliasing write, was error prone.
Q3: How, if at all, would this analysis fit into a development workflow or CI/CD pipeline?
We can split this into two parts: inline analysis as the developer is writing code, versus analysis of an entire codebase. In both cases, as with any kind of analysis, the question we are trying to answer is “Will this have meaningful impact, without negatively impacting development velocity or annoying the developers”. However, the actual work a developer may have to do to respond to an alert (in terms of reasoning, coding and validation of results) is drastically different between these two scenarios, and so we need two different modes of operation.
In the case of a developer writing a new piece of code, if their IDE alerts them to a loop matching the properties we’re looking for, it is likely to be an easy decision as to whether to adjust the code or not. They will have some idea as to whether the code is likely to be “hot”, and what the impact of that may be. As the code is new, there’s no prior version to benchmark against, no resistance is likely to be encountered in the PR review process (again, no previous code being changed), and if the fix is something like “use char8_t instead of char” then the developer is likely to do it as there is no cost to them. In security this is a similar scenario to your IDE alerting you to use of a potentially unsafe function. Even if you know the code will never be reachable via an attacker, you may use the proposed safe version anyway just to shut up the linter and to follow best practices.
The case of analysing an entire code-base is a bit more tricky. One of the problems with static analysis in security is that if your automated analysis is purely static, it is easy to end up drowning in low/no-impact reports in this scenario. This is why fuzzing is so appealing: assuming you are providing fuzz inputs through the same input interface that an attacker can access, you generally know that each issue found is both a true positive and worth solving.
For performance issues, we have a similar problem with static analysis: given a result set, we may find it difficult to know where to put our energy in terms of what to first triage, and then fix. We are not likely to have the time to fix everything, and even if we do, the process of validating those fixes and getting them through a PR review may be a significant effort. So, how do we get something akin to fuzzing’s clarity of signal?
Continuous profiling in production will give it to us quite easily. The results of the CodeQL queries can be ranked based on the CPU consumption observed by the profiler in the real world, and the developer’s efforts therefore focused on findings most likely to have meaningful impact.
Conclusion/Open Questions/Future Work
Practical static analysis for performance analysis is a wide open topic. However, regardless of what direction it takes, the best results will be achieved in conjunction with data from continuous profiling. As outlined in the previous post, there are at least three ways to do this combination: context-for-ranking in which continuous profiling is used to rank the output of a static analysis, context-for-operation in which the static analyser requires data from continuous profiling to operate at all, and ranking-for-analysis, in which we have a heavyweight, slow, static analysis that doesn’t scale to an entire codebase, and therefore continuous profiling is used to guide where to target it.
In this post we saw an example of an analysis that requires context-for-ranking from a profiler. Without it, false positives, and the non-negligible effort required to triage, fix and benchmark each finding, means developers will lose patience with the tool after burning their energy on irrelevant findings, even if they turn out to be fixable true positives. A profiler changes this dynamic, ensuring that the developer’s efforts are focused on findings that are most likely to have a meaningful impact on performance.
As for using CodeQL for this sort of pattern matching, the experiments I did for this post were enough to convince me it’s worth investigating further. I found some good results, that lead to meaningful performance improvements, yet at the same time there were some notable misses (the Linux kernel, PHP and Python), and the false positive rate combined with the effort to triage, fix and then benchmark changes, mean I still consider the approach to be “experimental” rather than developer ready. There are two big open questions for me:
- What sort of properties can we query for statically? The type aliasing issue is a quirk of C/C++’s type system. Are there other language-level properties we could capture similarly? Are there API usage patterns that lead to performance issues that we can query for? An example that comes to mind is the use of std::vector inside loops that would otherwise be vectorisable. My guess is there are a few such things, but the question is: how often do they occur, and how meaningful are they? Beyond these, in security, we have seen an evolution from looking for language and API specific issues, to looking for patterns that are specific to a particular code-base but tend to be frequently reintroduced and high impact. Would this be worth pursuing in performance as well? i.e. Are there performance bug types that may only be specific to, for example, Firefox, but that repeatedly occur there due to a particular internal API or pattern?
- Would it make more sense to do this analysis at the assembly level? Doing so would side-step the problem of having to try and encode how we think source code will be transformed into assembly, and it is the assembly that matters in the end. However, it can be more difficult to implement common static analysis algorithms on assembly, and scaling the analysis may prove more difficult. In reality, I expect both source level and assembly level analysers will be necessary. For many properties, the false positives introduced by working at the source level will either be irrelevant or manageable, and for those properties the convenience of working at a source level is attractive. Some other performance issues (e.g. assembling layout or alignment) can only be discovered by looking at the running binary though, and so a platform for writing and running analysis at this level will be necessary (e.g. Binary Ninja, IDA, Ghidra).
And that’s a wrap. If you made it this far I hope you found it interesting! If you’ve any questions, leave a comment below or you can find me on twitter @seanhn or LinkedIn.







